![[Kernel, courtesy IowaFarmer.com CornCam]](kernel.jpg)
Advanced Operating Systems, Fall 2004
Lecture 10 Preliminary Notes
BVT/L3 Microkernel
*** SCHEDULING COMPLETION: DEVELOPING BVT **
- Start from the basics: round-robin scheduling
-- Schedule the runnable processes in round-robin order
-- What does this look like?
-- Graph time quanta (X axis) vs. number of times each process is scheduled
(Y axis)
... A process that is not running shows up as a horizontal line
... When the process runs, it shows up as an arrow moving one unit
up (it ran once) and one unit right (it ran for one quantum)
-- Scheduling two processes in round-robin order:
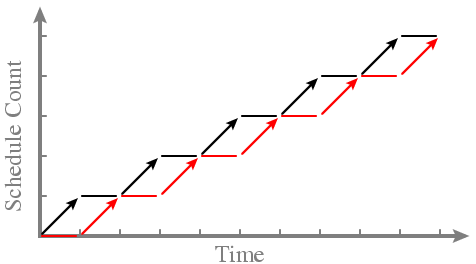
- Problem with round-robin order? -- PARAMETERS (in terms of the dimensions to the scheduling problem) -- Can't declare that one process should run more frequently than another - Proportional share example -- Say we want black to run twice as often as red -- Then black has share 2, and red has share 1 -- Example run:
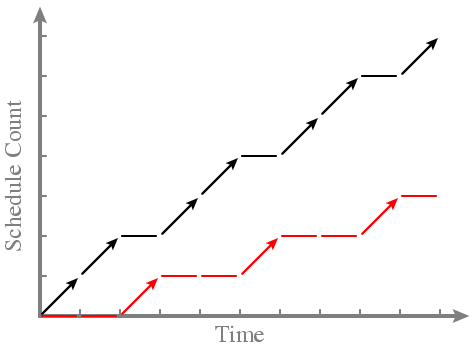
- This works, but hard to build a scheduling algorithm around it -- How can the kernel tell that black and red have run in the correct proportion? ... Could divide their Schedule Counts, compare against the ratio 2:1 ... That works, but doesn't easily tell you who to run next! -- Wanted: A single metric that tells the kernel who to run next ... Say, the process with the lowest metric ... Enables inexpensive data structures (heaps, priority queues) - Idea: Don't keep track of raw Schedule Count. Instead, keep track of the ratio "Schedule Count / Share"! -- Example:
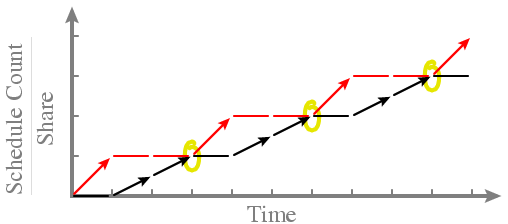
- What does this buy us?
-- Fairness becomes obvious
... Allocation has been fair when all processes have the same Y-value
(circled points)
-- Obvious who to run next
... The runnable process with the lowest Y-value
-- Note that processes with *higher* shares have *lower* slopes (black's
share is 2, so its slope is 1/2; red's is 1, so its slope is 1)
- Stride scheduling
-- Implements this idea
-- The ratio "Schedule Count / Share" is called the "pass"
-- Following BVT, we'll call it the "Virtual Time"
- What's nice about Virtual Time?
-- Simple algorithm decides what to run: Minimum virtual time
-- So by changing the way virtual time is calculated, we can cleanly
change scheduling behavior!
... Arguably much nicer than crapping up the algorithm with special cases
- Starting virtual time equation
-- After process i runs, VT_i += 1/share_i
-- Run process with minimal VT
- First extension: What about non-runnable (sleeping) processes?
-- Red becomes runnable at time 6
-- Show sleep with "S", wake with "W", sleeping processes are lighter
-- Graph:
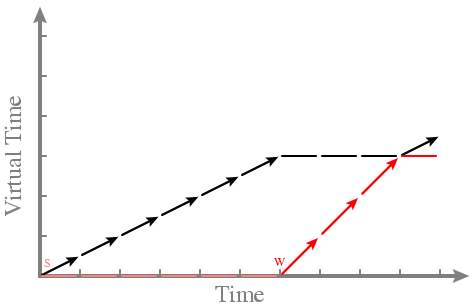
- Problem: FAIRNESS/STARVATION
-- Red got to run a long time, despite its low share
-- Want to resume normal scheduling when a process wakes up, not give
the process "credit" for its sleep time
- Solution: Add an operation
-- If a process falls behind during sleep, move its VT forward on wake so it's
greater than or equal to the earliest VT in the system
-- After process i runs, VT_i += 1/share_i
-- When process i wakes up, VT_i = max(VT_i, min_{j!=i} VT_j)
-- Run process with minimal VT
-- Graph:
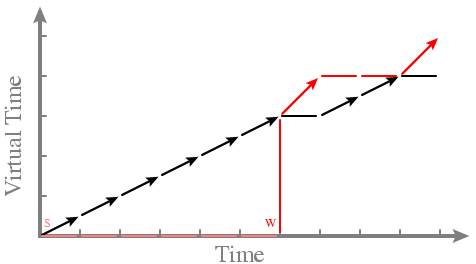
-- Now red and black run fairly even after red wakes - BVT extension: What about latency-sensitive threads? -- Can we achieve soft or hard real-time guarantees? -- Example: latency-sensitive blue thread wakes up at time 6
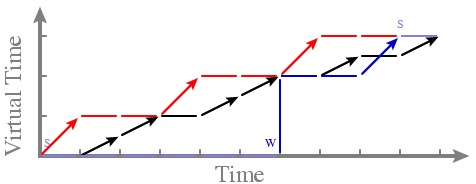
- Problem: DELAY
-- Blue has same VT as red and black; system chooses randomly to run red
and black first!
-- Not latency-sensitive; blue wants to run more quickly (in return for
running relatively rarely/not being a CPU hog)
- Solution: Add an operation
-- Don't use straight VT
-- Instead, add a fudge factor, the warp, that's 0 for normal
threads and nonzero for latency-sensitive threads
-- Warped threads should run as soon as they are scheduled
-- How? Subtraction!
-- After process i runs, VT_i += 1/share_i
-- When process i wakes up, VT_i = max(VT_i, min_{j!=i} VT_j)
-- Set effective virtual time EVT_i = VT_i - W_i (the warp)
-- Run process with minimal EVT
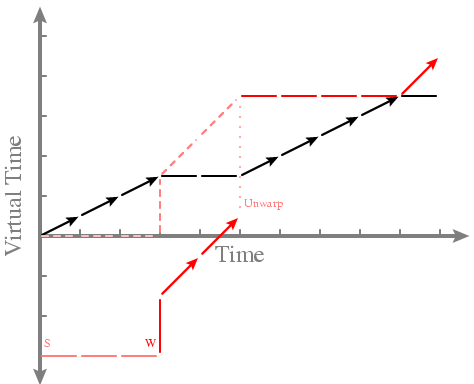
-- Example
... Solid lines are EVT, dashed lines are VT
... Black runs unwarped
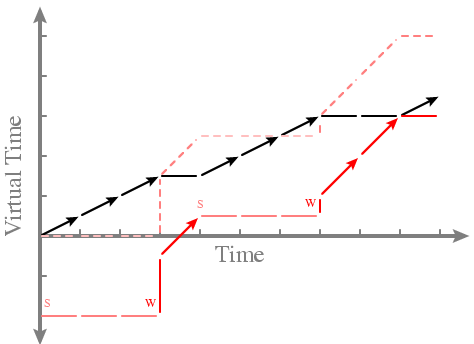
-- It works! Warped threads appear to have lower passes, so they run as soon as they're scheduled - Is this fair? -- Yes, over the long term -- Example: Red stays runnable
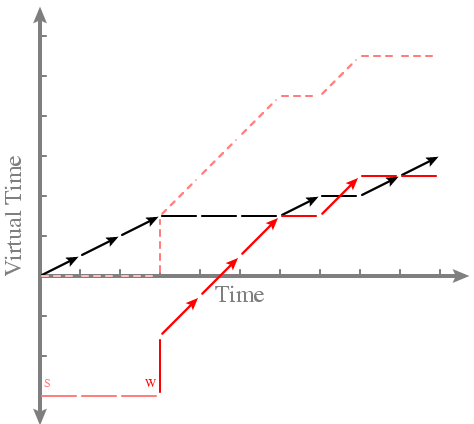
-- After time 6 black and red run according to their shares
- Problem: Can we get rid of the little burst of starvation?
-- Yes: Add an operation
-- Don't let a process run warped for too long
-- Don't let a process re-warp until enough time has passed
-- After process i runs, VT_i += 1/share_i
-- When process i wakes up, VT_i = max(VT_i, min_{j!=i} VT_j)
-- Set effective virtual time EVT_i = VT_i - (warp ? W_i : 0)
-- Add parameters L_i (warp time limit) and U_i (unwarp time requirement)
-- warp = user_i_wants_to_warp
&& current_warp_duration < L_i && time_since_last_warp >= U_i
... (Roughly; need suitable corner cases)
-- Run process with minimal EVT
-- Example:
- Can we go further? -- Example: multiprocessor affinity: EVT_i = VT_i - (warp ? W_i : 0) + M_i, for M_i the migration penalty to discourage the scheduler from ping-ponging a process between CPUs -- Design hint: A very good idea to look for this type of basic parameter! *** L3 and MICROKERNELS *** - Microkernels -- Idea: Implement many traditional OS abstractions in servers ... Paging, File system, possibly even interrupt handlers (like L3) -- Advantages: Modularity, extensibility, fault isolation, ... -- Disadvantage: Performance ... What would be simple calls into the kernel are now IPCs ... How bad is performance? Look at Table 2 (p. 12) - Opinions on microkernels! -- Tanenbaum (microkernel designer) vs. Torvalds (Linux is a monolithic kernel ["macrokernel"]):
Microkernels Revisited [Tanenbaum, 2004]
I can't resist saying a few words about microkernels. A microkernel is a very small kernel. If the file system runs inside the kernel, it is NOT a microkernel. The microkernel should handle low-level process management, scheduling, interprocess communication, interrupt handling, and the basics of memory management and little else. The core microkernel of MINIX 1.0 was under 1400 lines of C and assembler. To that you have to add the headers and device drivers, but the totality of everything that ran in kernel mode was under 5000 lines. Microsoft claimed that Windows NT 3.51 was a microkernel. It wasn't. It wasn't even close. Even they dropped the claim with NT 4.0. Some microkernels have been quite successful, such as QNX and L4. I can't for the life of me see why people object to the 20% performance hit a microkernel might give you when they program in languages like Java and Perl where you often get a factor 20x performance hit. What's the big deal about turning a 3.0 GHz PC into a 2.4 GHz PC due to a microkernel? Surely you once bought a machine appreciably slower than 2.4 GHz and were very happy with it. I would easily give up 20% in performance for a system that was robust, reliable, and wasn't susceptible to many of the ills we see in today's massive operating systems.
- From a 1992 discussion (this message by Tanenbaum, quotes from Torvalds):Re 2: your job is being a professor and researcher: That's one hell of a good excuse for some of the brain-damages of minix. I can only hope (and assume) that Amoeba doesn't suck like minix does. Amoeba was not designed to run on an 8088 with no hard disk. If this was the only criterion for the "goodness" of a kernel, you'd be right. What you don't mention is that minix doesn't do the micro-kernel thing very well, and has problems with real multitasking (in the kernel). If I had made an OS that had problems with a multithreading filesystem, I wouldn't be so fast to condemn others: in fact, I'd do my damndest to make others forget about the fiasco. A multithreaded file system is only a performance hack. When there is only one job active, the normal case on a small PC, it buys you nothing and adds complexity to the code. On machines fast enough to support multiple users, you probably have enough buffer cache to insure a hit cache hit rate, in which case multithreading also buys you nothing. It is only a win when there are multiple processes actually doing real disk I/O. Whether it is worth making the system more complicated for this case is at least debatable. I still maintain the point that designing a monolithic kernel in 1991 is a fundamental error. Be thankful you are not my student. You would not get a high grade for such a design :-)- Minimum needed to do an IPC -- See Table 3, p. 15: 127 cycles -- What's expensive here? ... int, iret. Flushes pipeline, stack manipulations... ... TLB misses. Why are 5 TLB misses necessary? B's thread control block loading %cr3 flushes TLB, so kernel text causes miss iret, accesses both stack and user text - two pages B's user code looks at message -- How has this trend has progressed since the paper? ... Worse now. Faster processors optimized for straight-line code ... Traps/Exceptions flush deeper pipeline, cache misses cost more cycles -- Actual IPC time of optimized L3: 5 usec - L3 principles -- *IPC performance is the master* -- Plus a bunch of other things that emphasize IPC performance - All design decisions require a *performance discussion* - If something performs poorly, look for new techniques - *Synergistic effects* have to be taken into consideration [What does this mean? That a lot of little things might add up to a big gain, or a big loss if two changes interact poorly. Need to test each combination of features?!] - The design has to *cover all levels* from architecture down to coding - The design has to be made on a *concrete basis* -- Up until this point, a bunch of principles that argue that you should do endless IPC optimization! ... How do we know when to stop? ... How do we know when we can't optimize further? -- Answer: One of the nicer principles in L3: - The design has to aim at a concrete performance goal -- Without this, you'd get lost optimizing things that don't matter -- Take minimum IPC time, multiply by 2 -- 350 cycles = 7 usec = T -- Minimum null RPC is already at 69% T! -- System calls + address space switches = 60% T -- L3 achieves 250 cycles = 5 usec -- Basic approach: Design the microkernel for a specific CPU - IPC interface send (threadID, send-message, timeout); /* nonblocking */ receive (receive-message, timeout); /* nonblocking */ /* These interfaces are expected to be the ones used most often */ call (threadID, send-message, receive-message, timeout); reply_and_receive_next (reply-message, receive-message, timeout); ** Optimizations ** New system call: reply_and_receive_next. Effect: 2 system calls per RPC, not 4 - Why? Want to combine kernel crossings (60% T) Complex messages: direct string, indirect strings, and memory objects. - Direct string mandatory - Direct/indirect strings copied - Memory objects copied "lazily" by VM remap operations - Why? Remove need for multiple messages if you want to send a lot of data; again, eliminate kernel crossings (60% T) - Receive directly into buffers chosen by the user - Communication windows -- How to transfer data between the two address spaces? ... Copy? => 20 + 3n/4 cycles for an n-byte message: n=8 ==> 0.5 usec = 10% T That's 2 copies: A->K->B Two copies are *required* for buffering, but not if recv space avail Can we optimize if receiver space is available? -- Optimization attempts ... Shared memory, mutually read-write? Considered a bad abstraction! Multi-level security (makes it hard to reason about information flow) For instance, can you implement "Untrusted can send a message to Secret, but not vice versa"? Receiver can't check message legality (might change after check) When server has many clients, could run out of virtual address space Requires shared memory region to be established ahead of time Not application friendly, since data may already be at another address Meaning applications would have to copy anyway--possibly more copies One way microkernels and exokernels are different: microkernel cares more about application programming interface -- Solution: Communication window ... Kernel copies data once, not twice: A->remapped B ... How to do this maximally cheaply? ... Copy two PDE's (8MB) from B's address space into kernel range of A's pgdir Then execute the copy in A's kernel space ... What do we need to do to the PDEs? Literal copy? No: remove PTE_U permission ... Why two PDEs? Maximum message size is 4 Meg, so the copy is guaranteed to work regardless of how B aligned the message buffer ... Why not just copy PTEs? Would be much more expensive ... What does it mean for the TLB to be "window clean"? Why do we care? Means TLB contains no mappings within communication window We care because mapping is cheap (copy PDE), but invalidation not x86 only lets you invalidate one page at a time, or whole TLB We need to invalidate because the same kernel virtaddr space may refer to multiple physical pages Does TLB invalidation of communication window turn out to be a problem? Not usually, because have to load %cr3 during IPC anyway Unless the address space doesn't change or used nonblocking calls - Thread control block (tcb) tcb contains basic info about thread registers, links for various doubly-linked lists, pgdir, uid, ... commonly accessed fields packed together on the same cache line like JOS 'struct Env' Kernel stack is on same page as tcb. Why? Minimizes TLB misses (since accessing kernel stack will bring in tcb) Allows very efficient access to tcb -- just mask off lower 12 bits of %esp With VM, can use lower 32-bits of thread id to indicate which tcb Using one page per tcb means no need to check if thread is swapped out Can simply not map that tcb if shouldn't access it Sort of bit swizzling! Thread ID = JOS envID - Thread queues -- Ready queue, 8 timeout queues, maybe a long-term timeout queue, busy queue, present queue, waiting-on-thread-T queue ... Use doubly-linked list ... Invariant: no page faults when traversing queues so remove from all queues before unmapping -- Lazy scheduling ... Conventional approach to scheduling: A sends message to B: Move A from ready queue to waiting queue Move B from waiting queue to ready queue This requires 58 cycles, including 4 TLB misses (1.2 musec, 23% T) One TLB miss each for head of ready and waiting queues One TLB miss each for previous queue element during the remove ... How can we improve this? Insight: After A blocks, *don't take it off the ready queue yet!* It will probably get right back on very quickly. Ready queue must contain all ready threads, EXCEPT POSSIBLY CURRENT ONE Might contain other threads that aren't actually ready, though Each wakeup queue contains AT LEAST all threads waiting in that queue Again, might contain other threads, too Scheduler removes inappropriate queue entries when scanning queue Why does this help performance? Only three situations in which thread gives up CPU but stays ready: send syscall (as opposed to call), preemption, and hardware interrupts So very often can IPC into thread while not putting it on ready list "ipc : lazy queue update" ratio can reach 50:1 with high ipc rates - Lots of other optimizations too (see paper) - Great performance numbers! Much better than other microkernels -- Too bad microbenchmark performance might not matter (exokernel) -- Too bad, too, that hardware evolution has made ipc inherently more expensive