Outline, via pseodocode
main() {
char buf[...];
while (!feof(stdin)) {
read_frame(&buf[0]);
process_audio(buf, &audio_opts);
process_video(buf, &video_opts);
}
}
Question: What is the problem with this code?
Answer: The audio and video are processed sequentially. We want the audio and video to happen at the same time!
Suppose we have no threads. -> we use processes for process_ functions.
2 processes are needed -> so we have one fork() call.
Revised code
pid_t audio;
audio = fork();
if (audio == 0) {
process_audio(buf, &audio_opts); // Child process
}
else {
process_video(buf, &audio_opts); // Parent process
}
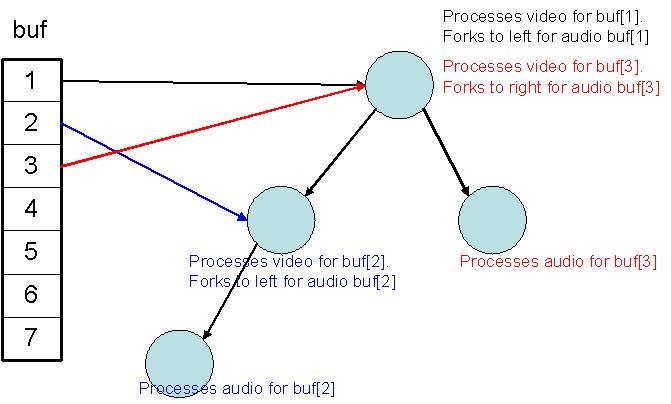
Problem with this code: the process is going to end up moving on to next frame when done with reading. (without processing) Look at diagram for illustration.
| Diagram: | |
| Supposing audio process ends earlier than video process |
Solution: Add exit(0) call after process_audio() function.
But we're still not done. There's a lot of overhead to this design, since we fork a new process on every frame, which involves potentially copying a lot of the address space and other resources. Can we avoid that overhead? Yes---this is what threads are for.
Threads (on Linux systems) are brought to you by the clone() syscall. However clone is rarely called directly because of portability issues, instead we use the pthreads library. Some examples follow.
Creating a simple thread:
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
void *thread_foo(void *arg) {
printf("Processes, fibers, and threads, Oh my!\n");
}
int main() {
pthread_t teddy_the_thread;
if (pthread_create(&teddy_the_thread, NULL, thread_foo, NULL)) {
printf("error creating teddy");
abort();
}
if (pthread_join(teddy_the_thread, NULL)) {
printf("error joining");
abort();
}
}
Pthreads take a function pointer as an arguement, this function is what the thread executes while its running. The pthread_join function is similiar to the wait() family of functions, that we use with fork, join returns only when the thread that its called with exits.
Here's an example with two threads and a mutex:
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
pthread_mutex_t mut = PTHREAD_MUTEX_INITIALIZER;
int count = 0;
void *plus_one(void *arg) {
sleep(rand() % 3);
pthread_mutex_lock(&mut);
count++;
printf("Count is: %i", count);
pthread_mutex_unlock(&mut);
}
int main() {
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, plus_one, NULL);
pthread_create(&thread2, NULL, plus_one, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
}
This example just demonstrates that the pthreads library provides various synchronization facilities that we could use in our software.
MP3 player from above, using thread calls in pseudo code.
char buf[...]; //global variable
process_audio(*opts);
main() {
while() {
read_frame(buf);
pthread_t pt;
if (pthread_create(&pt, NULL, process_audio, &aopts) < 0)
//process_audio is the name of the function to run. Create returns only in parent.
abort;
process_video(buf, &vopts);
//returnvalue is void * rather than integer status. This is equivalent to wait.
pthread_join(pt, &returnvalue);
waitpid();
}
}
Please see this handout for more examples of thread syntax.
| Memory | |||||||
|
 Call new function Call new function |  Return from function Return from function |
Threads typically have the same memory space as their parent with the exception of the stack, registers, and of course the program counter. Since threads have separate stacks within the same memory space as other threads it is possible that their stacks grow into each other.
2 threads -> may interfere with stacks.
Creating a stack => Unprivileged.
New thread structure in kernel
->New copy of registers Only to OS
There are typically two types of threads, User threads and Kernel Threads. Kernel threads (1:1 threads) are created using syscalls, and therefore the kernel maintains a limited state about each thread and can schedule each thread independently of the parent process. Some tasks can be better solved once divided up into many smaller execution cycles. The problem is the overhead of process context switching, while threads are not a perfect solution, at times it becomes neccessary to provide thread support when the OS has none. User threads ar contained entirely within a single process and perform some type of ad-hoc scheduling between the threads within the context of a single process. An unprivileged process can provide all the funtionality we'd expect from threads (registers, shared memory and stack) except for the preemptive scheduling, which requires kernel support for security reasons. However user threads tend to provide scheduling functionality cooperatively, each thread willingly gives up the CPU usually when executing an IO intensive syscall. Therefore the context switch overhead with user threads is less then that of kernel threads.
| Kernel Threads | User Threads |
|
|
The goal of scheduling is to efficently provide the illusion that multiple processes are executing concurrently when in reality the processor can only execute a single process at a time.
Suppose OS has n CPUs that want to do work, and m > n jobs wanting to run
Problem: Which jobs get run first, and what order are they run in?
GOAL:
High level – Make n CPUs look like 1 CPU per process.
Concrete goals / OS goals:
ALGORITHM 1: FIFO / First Come First Served
Gantt Chart – diagram of processes running in time
| time-> | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| process | A | B | C | D | ||||||||||||||||
Context switch at 5, 7, 16, 20 – each switch consumes some time C (but ignore for now)
CPU utitlization approx 1, if account for context switches:
20 / (20 + 3C)
T trnd (avg) = (5 + 7 + 16 + 20 ) / 4 = 12 (again, approx)
Waiting time = (0 + 5 + 7 + 16) / 4 = 7
Throughput = 4/20 = 0.2 jobs/unit time. No stravation
ALGORITHM 2: Shortest Job First
When you have a choice, pick the process that has least work to do.
| time-> | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| process | B | D | A | C | |||||||||||||||||
T trnd (avg) = (2 + 6 + 11 + 20 ) / 4 = 9 3/4 + 1 1/2 C
Waiting time = (0 + 2 + 6 + 11) / 4 = 4 3/4
Minimizes waiting time. (optimal)
However, long jobs could starve eventually. There also needs to be a way to
calculate execution time beforehand.
ALGORITHM 3: Round Robin with Preemption
Quantum: number of time units between preemptions.
| time-> | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| process | A | B | C | D | A | C | D | C | ||||||||||||
in this example, quantum Q = 3.
Total of 7 context switchs -> at least 1 per quantum.
T trnd (avg) = 12 3/4 + 4 1/2 C
Waiting time = 4
In case of lower q, it will raise T trnd (more context switch) but lower waiting time.
This is FAIR.
*What determines quantum and how do we set it?
Timer interrupt frequency determined quantum. We can set hardware.
Ranges from 100ms for BSDS to 1ms for Linux.
ALGORITHM 4: With strict priority
Run the process with highest priority (represented by lower numbers.)
If there is a choice, run those round robin.
| C = 0 | High |
| D = 1 | prio |
| A, B = 2 | Low |
This algorithm is not fair.
| time-> | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| process | C | C | C | D | D | A | B | A | ||||||||||||
This is pre-emption with priority, will pick up at the next lecture.