CS111 Scribe Notes: Lecture 11/17/05
Ryan Hall Sarah Volden Jeff Mascia
New Grading
1/3 tests
1/3 labs
1/3 other -> 2 reports, 1 minilab, challenge presentation, scribe notes
File Systems
Disks have improved by price/byte more than speed
Down to pennies a gigabyte
Disk File Semantics
· The most important thing we expect from a disk file is persistence:
it needs to survive a reboot, it needs to survive a crash as well.
· This leads to make file systems more robust.
· All modern disks provide a byte stream, random access
- This means we can quickly skip n bytes of data
- We can rewind to the beginning of the file, fast forward to the end
- A pipe does not have these semantics – Why not? Doesn’t make sense because it goes one way.
There is no way to ask the other end of the pipe to start over.
· Expect each file to have a name, and to be located in a directory (group of file)
· Expect the file to have some kind of access control
(which users can access this file – is this access read or write?)
· Our goal is to change this mechanical device into a file system where we can access files very quickly
Kernel Structures for Disk Files
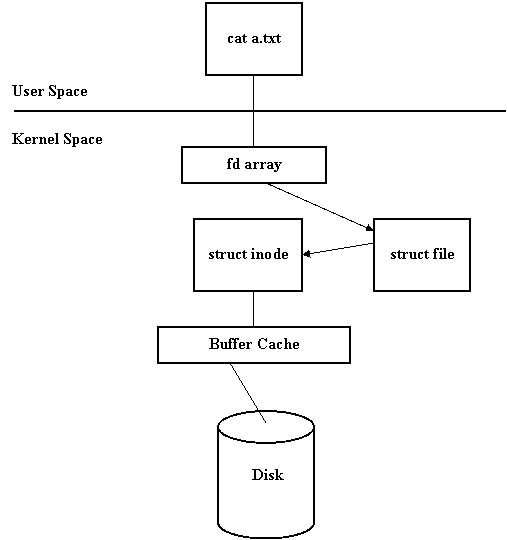
· Cannot create file descriptor before accessing disk
· Before opening file, we need to check:
1. That the file exists
2. Access rights allow us to open the file
· We call the contents of the file, DATA
· We call file size, file name, type, owner, access rights, METADATA
· METADATA is also persistent so it must be stored on disk
· Before opening file, we must load in metadata from disk
· The kernel has a structure, struct inode, that holds the metadata
· Accessed by loading the information from the directory on disk
· Now we create the struct file
· The file descriptor array is essentially an array of pointers to struct files
· Struct file points to struct inode
Performance
· Bad way to implement a file system: On every block, we are going to wake up the hard disk,
read that block, park the hard disk
· Why is this bad? There are always 2 seeks per block!
· To read a.txt we need to:
- Read inode metadata (2 seeks); read each block in the file (2x # blocks seeks)
· To improve performance:
- We are going to try to cache disk blocks
- The place where disk blocks are cached is called the buffer cache
- The buffer cache is located on the controller and not the hard drive
- Although the hard drive can have is own cache,
we worry about the buffer cache because we can control it
- Prefetching: Load cache with data that should be used soon
- Buffer cache is basically a map of disk blocks numbers that gives
memory page containing that data or page fault
Buffer Cache:
Handles swapping, memory mapped files
· Speed up performance:
- When an app opens a file, prefetch its data
- Problem: What if we have a 4 terabyte database.
Databases are not accessed sequentially. Prefetching wouldn’t work.
- You need to know what kind of file you want.
- Easy to prefetch small files
Disk Layout

· The very first block on a start up disk is the boot sector and also partitioning information
· The next sector is called a superblock and hold data about how the disk is laid out
· The superblock contains: disk size, filesystems, parameters (METADATA)
· The rest of the blocks consists of directories, file metadata, file data and free space
· We want file data and metadata to be located in close proximity
Why is that? Because of locality of reference.
· First suggestion is to place metadata before data. This is ideal, but it causes external fragmentation.
Contiguous allocation has fragmentation.
· Lets do page allocation
· Free block list will have each block point to the next free block
· Allocate a block for A’s metadata and then enough blocks for A’s Data
· We can do a factor of 10 better than this. What is the problem with this?
When the free list is being used, it becomes completely random which causes lots of seeks.
The pattern of seeks equals the pattern of the free list.
· If we keep the list in close proximity, it is easy to sort and easy to find free blocks that are close to each other
File Allocation Table (FAT)

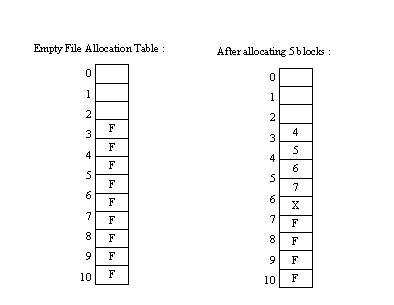
· Take out all the free block pointers and place them in an array on the disk
· 0 is not free because it’s the boot sector, 1 is not free because it’s the superblock
and 2 is not free because it’s the FAT
· The rest are available
· Allocate N blocks
- Look for N free blocks in close proximity and mark as allocated
· In the file metadata, say the first block in the file = 3. The next block can be found in the FAT data for 3.
This creates a link list in the FAT.
· The problem is locating a given offset O(n) operation where n is the offset
· For large files, O(n) is bad
Goal:
· Design a File System with O(1) file offset time
· We want to have an array of the blocks in the file, which is part of the file metadata
· A large array might spread across multiple blocks causing fragmentation
· Don’t want linked list access (not O(1)) so we use a layer of indirection -> tree

· We have 10 direct blocks (each 4KB) so we have 40 KB
· If we have a larger file, we use the indirect block pointer to point to a block that contains only block pointers.
This holds 10 to 1033 blocks.
· Size of file that uses 1 indirect block is roughly 4MB
· If we need more size, we use a doubly indirect block pointer to point to a double indirect block
which points to indirect blocks which each point to blocks. This allows 4GB files.
· If more is needed a triply indirect pointer is used for 4TB.
· For free blocks, uses free block bitmap where each block gets a bit (1 for free 0 for allocated)

Slightly higher storage overhead for pointers
Directories
· Hierarchical tree
· Every file is in a directory
· Every directory is either
- root
- subdirectory
Representing directories?
· Directory is a special type of file
· Optimize proximity:
- Metadata in directory
![]()

· Actual file systems:
- Pointer to metadata inode number
- This makes it cheap to move a file between directories
- Makes a possible robust move between directories
· Since we only have a pointer to the metadata and not the metadata in the directory,
we can have a file point to two different directories.
· Must store # links because we can only free the data blocks when the number of links reaches 0
Want to move /a/b.txt to /c/d.txt.
No matter when the system crashes, I must not lose the file
First try: Free the old directory entry, then write the new directory entry.
Problem: If I crash in the middle, then the file is gone

Second try: Write new directory entry and then free old directory
Problem: Blocks can get reused
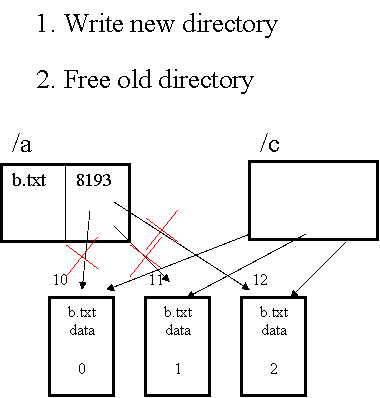
Third try: Separate inodes. Write new directory entry. Update link
count. Free the old. Update the link count.
· When you don’t shutdown properly (system crash), the slow moving bar is looking for
the case when the system crash happens before update link. This file system checking
can resolve a crash to a good state without allocating blocks.
· We don’t want directories to have more than one director link! Why? We don’t want to have
circular directories, so the OS just doesn’t allow any directory linking. In order to free the
circular directories we would have to garbage collect, which is very slow because of the slow seeks.
· We want all data blocks for files in directory A to be in proximity.
· Does it make sense to put file data far away? Why?
· Break large files up and place far away from each other to make room for small files in the same directory.
· Large files are already slow, leave room to keep small files fast.
· How do we write data to disk/read it from disk?
- Performance: minimize seeks
· Service requests FCFS
- Lots of seeks
· Shortest seek time first
- Examine head position and service closest request
- This will cause starvation
· Circular Scan/Look
- Travel across the disk and service request as they arise (2,4,1,3,5)