|
One rich source of attacks has been due to the fact that virtually all operating systems and most systems programs are written in C Programming language. Unfortunately, no C compiler does array bound checking. Consequently, if the program fails to ensure that the length of the data entered is equal to or smaller than the data buffer allocated for its storage, then any overflow data will simply be written over whatever happens to be after the data buffer. The following program is one example of such programs.
f()
{
char buf[1024];
while (more chars)
buf++ = read();
}
|
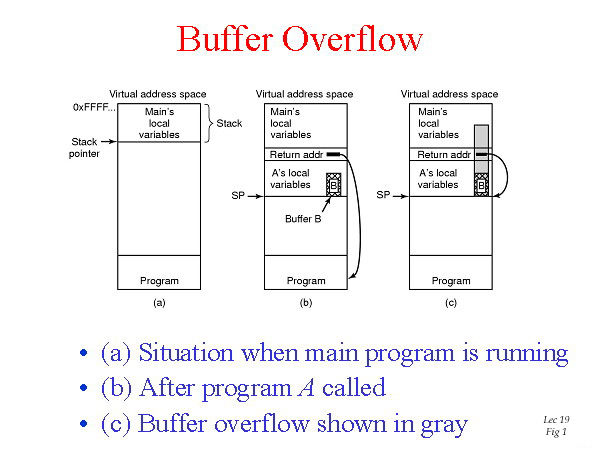
This property of C leads to attacks of the following kind. In Fig. 1(a), we see the main program running, with its local variables on the stack. At some point it calls a procedure A, as shown in Fig. 1(b). The standard calling sequence starts out by pushing the return address onto the stack. It then transfers control to A, which decrements the stack pointer to allocate storage for its local variables. Suppose A has a finxed-size buffer of 1024 bytes. If the amount of data provided by the user of the program is more than 1024 bytes, a buffer overflow occurs and memory is overwritten as shown in the gray area of Fig. 1(c). Worse yet, if the data is large enough, it also overwrites the return address. If the buffer contains a malicious program and the layout has been very, very carefully made so tht the word overlaying the return address just happens to be the address of the start of the program. What will happen is that when A returns, the program now in B will start executing. In effect, the attacker has inserted code into the program and gotten it executed.
Generally, the buffer overflow problem is caused by careless programming. Therefore, one solution is to simply check the length of input data, to ensure that it is not larger than the allocated data buffer. Another choice would be to use a programming language that does not allow programmer to code a buffer overflow bug, but doing so does not necessarily prevent buffer overflow. For example, Java, C#, and Perl have some mechanisms to make it difficult to have a buffer overflow, but they all have a lot of libraries written in C.
In order for the attack to succeed, the word overwriting the return address has to be the beginning address of the malicious program. The attacker has to know the position of stack pointer beforehand in order to make the precise layout. Therefore, another solution is to randomize stack pointer, thereby minimizing the exploitable invariants.
SQL injection is a security vulnerability that occurs in the database layer of an application. It's better explained with an example. Suppose in a database-backed web site, user enters username on a form, and server replies with address. Assume the following code is embedded in the server application.
string username = dom.getForm("username"); string query = "SELECT address FROM usertable WHERE uname = '"+username+"';" database.execute(query);
If the user types "eddie'; SELECT bankaccount FROM usertable WHERE uname = 'ahnuld'" as username, the following SQL statement would be built by the code above:
SELECT address FROM usertable WHERE uname = 'eddie'; SELECT bankaccount FROM usertable WHERE uname = 'ahnuld';
When sent to the database, this statement would be executed and Arnold's bankaccount would be sent to the user. I am sure our governor wouldn't be happy about it.
Each process has a UID and a GID, and they are inherited by children. Only root user can change its UID.
Each file in file system has UID and GID.
Permissions tell the user and the group what they can do and not do.
In Unix, when you type the command "ls -l", you will see the permissions on each file.
cs111> ls -l cs111> drwxrw-r-- 1 username groupname 100 Dec 25 00:00 filename
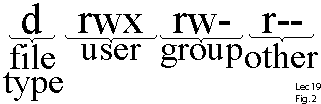
The first character indicates the type of file (d for directory, s for special file, - for a regular file). The next three characters ("rwx") describe the permissions of the user of the file. In this case, the user can read, write, and execute. The next three characters ("rw-") describe the permissions for those in the same group. The last three characters describe the permissions for all others.
An important question is how the system keeps track of which object belongs to which principal. Conceptually, one can envision a large matrix, with the rows being principals and the columns being objects. Each box lists the acess rights that the principal contains for the object. The following matrix is one example.
|
|
|
Objects
|
|||
|
|
|
/home/eddie
|
/home/eddie/grades
|
/home/bob/file
|
/etc/motd
|
|
Principals
|
Eddie
|
read, write, -
|
read, write
|
-,-,-
|
read,-,-
|
|
Bob
|
read, write, -
|
-,-,-
|
read, write, -
|
read,-,-
|
|
|
Lucifer
|
-,-,-
|
-,-,-
|
-,-,-
|
read,-,-
|
|
|
Mike/Chris
|
-,-,-
|
-,-,-
|
-,-,-
|
read,-,-
|
|
One potential problem of this particular access matrix is that even though Bob does not have permission to access the grades file, but he has access to the directory in which the grades file is placed. Since the directory operations require only directory privileges and removing a file turns out to be a directory operation, Bob can delete the grades file and create a new grades file. If he knows the format of the file, he can modified the grades without the Professor knowing it.
The login program is responsible for authenticating a user and granting him or her access to a machine. On Linux, the login programs works by first searching the /etc/passwd file for the particular user's password hash. It then computes the hash of the password the user entered and compares this value to hash stored in the password file. If these two hashed values match, it can then fork off the user's preferred login shell. Because this new login shell must run as though it was a process owned by the authenticated user, the login program must change the new process's ownership field. This tells us that the login program must be a priviledged application run as root, because only root has the ability to change process ownership.
Access matrices can be implemented in two different ways:
With access control lists each object lists all of its associated access rights. Going back to the access diagram, this means that access is defined by grouping the columns of the access matrix. As an example, UNIX files are implemented as access control lists because each file in the system defines three access rights: read, write, and execute. In order to associate these access rights with principals, each file on the system is owned by a certain user and a group. Given these file ownerships, every file on UNIX defines access rights for three principals: the user that owns the file, the group that owns the file, and everyone else.
With capabilities, each principal has a list of access rights its allowed to exercise. Thus, in this scenario the access matrix is grouped by rows. A good example of capabilities are file descriptors because they are objects that correspond directly to a principal (in this case, the principal being a user). The pros and cons of capabilities are precisely the opposite of those for access control lists:
Cryptography is used in order to ensure that a secret is kept a secret. Here is some basic terminology associated with cryptography:
Encryption - a process used in order to keep the contents of a document secret from attackers.
Authentication - verifying that a party in a message exchange knows some secret, hence verifying their identity.
The Login Program: As mentioned, the login program is a process running as root that starts up a user shell based on the user who is trying to gain access to the machine. The problem is how to correctly identify that the user who typed in his or her username is in fact that user?
To solve this problem, we must expect the user to know a secret. Then we can check the user’s secret against a version known to system, and thus make a decision on whether to authorize this user access to the system.
On UNIX systems, these secrets along with other user related data are stored in the /etc/passwd file:
/etc/passwd |
The problem is
we don’t want to store these passwords in plain-text format on the disk
because
they can be easily accessible by others who have sufficient privileges
on the system. Thus we need to
develop some mathematics that will allow us convert arbitrarily long
messages into cryptographic hashes,
such that the original message may be difficult to recover given the
hash value. Once we have developed such
a method, the hash of the password will be stored on the disk. Each
time a user is being authenticated, the
login program computes the hash of the password and compares this with
the version that exists on the disk. Now it is nearly impossible for a
user to get the password because a hash function is very difficult to
invert. An
even better method would be to utilize a cryptographic hash in which a
password
is hashed into a hashed value:
| H(y) = H(x) |
This way, it would be
very
difficult to find y. (NOTE: Here difficult means exponential time.)
Users need to be very
careful when
choosing passwords. It has been found that users often choose passwords
badly,
and are subject to what is know as a dictionary
attack. A dictionary attack is the general technique of trying to
guess
some secret by running through a list of likely possibilities. This list of possibilities is often a list of
words from a dictionary. The attack works because users often choose
easy to
decipher passwords! Go figure!
Betty
-> server: H(password)
|
Betty
-> server: Hi
server
-> Betty: KBS
Betty -> server: {H(password)}KBS |
encrypt(plaintext)
-> cipher text
decrypt(cipher text) -> plaintext |
encrypt
(P, K) = C
decrypt (C, K) = P |
encrypt
(P, Ke) = C
decrypt (C, Kd) = P |
Betty
-> server: Hi
Server
-> Betty: Kse
Betty -> server: {(H(password)} Kse |
Betty
-> server: Hi
Server
-> Betty: Kse,
NONCE
Betty -> server: {(H(password), NONCE} Kse |
Betty
-> server: Hi
(Say
attacker, E, intercepts the message at this
point.)
E
-> server: Hi
server -> E: Kse,
NONCE
server
-> Betty: Kse,
NONCE
Betty -> server: {(H(password), NONCE} Kse |
Betty
-> server: Hi
Server
-> Betty: {NONCE} Kbe
Betty
-> server: NONCE
|
Betty
-> server: Hi
Server
-> Betty: { Kse
} Kbe
Betty -> server: NONCE |