CS 111
Scribe Notes for 5/23/05
By Adriana Magaña, Brian Nguyen, Jesen Kwok Ha
File Systems
There are three key concepts that are taken into consideration in the design and use of file systems:
- Performance
- Robustness
- Overhead
File System Invariants
For most modern file systems, if these invariants are broken, the file system will become inconsistent: that is, broken, and will eventually violate what the user expects. (For instance, writing data into one file might change a completely different file as well.)
- All blocks pointed to are not marked free
- All blocks not pointed to are marked free
- No block belongs to more than one file
But following these invariants naively makes the file system
implementation quite slow, because it strongly constrains the order in
which the OS can write blocks to disk; these constraints leave the OS less
free to choose a fast disk schedule. And if we don't guarantee the
environments we risk corruption, or we need to fsck on
startup, which takes forever. So can we maintain the invariants
without constraining scheduling?
Soft Updates maintains these invariants by doing the following:
- Never point to a data structure before initializing it
- Never reuse a structure before nullifying pointers to it
- Never reset last pointer to live structure before setting a new one
- Always mark free-block bitmap entries as used before making the directory entry point to it
Follow these rules and the invariants will hold: cool! The neat aspect of soft updates is how it follows the rules without constraining scheduling order, through rollbacks and roll-forwards.
Journaling File System
But there are other efficient ways to achieve consistency too.
In a journaling file system, all changes are written sequentially to a log. The log is usually kept in a separate section of the file system. The log is written before the actual changes are written to the "real" data structures. Now there's no need to carefully put disk writes in order (like soft updates does); file system consistency is maintained by finishing transactions that were recorded in the log but that weren’t completed because of some type of failure like a system crash. Any unfinished log entries can be ignored; since we write the log before the real disk structures, if we crashed during a write to the log, then the real disk structures are safe.
Here are the steps taken by a Journaling File System when about to perform some FS operation:
- before doing any operations, it writes down the operation into a journal
- the operation is performed and written to the FS
- the journal entry is marked as done
This type of FS can be slower because it has to write to both the file system and the journal. On the other hand, the journal is written sequentially, so the FS will achieve good locality.
What should we write into the journal? There are two possibilities: full data journaling and metadata journaling. In full data journaling, everything is written to the journal, including data blocks. This provides a strong guarantee: No matter when the computer crashes, any write will either succeed or it will be like the write never happened. This is stronger than soft updates, which just says that the disk's METADATA will be consistent. However, it is quite expensive. Metadata journaling provides a weaker, soft-updates-like guarantee: No matter when the computer crashes, the file system metadata will be easy to make consistent. But it is a lot faster.
| Performance | slower by 2-3 times |
| Robustness | Full data journaling => very reliable; metadata journaling => only guarantees consistency |
| Overhead | Linux ext3: 32MB/disk; Linux JFS: 0.4% |
Journaling file systems arose out of an idea called log-structured file systems, where the entire file system data structure is just a journal!
Block Allocation
OK, so say that a file system needs to allocate a block for a file (because the file got bigger). How should we do it?
Why not choose any available block at random? This will work OK, but it won't help keep blocks of the same file together. That is, locality of reference will no longer imply proximity on disk. There will be a lot of seeks, so performance will be bad.
The BSD operating systems' Fast File System (FFS) allocates blocks using cylinder groups, an idea that has made its way into other FSes. The disk is divided into several contiguous groups of cylinders. Each cylinder group has its own free block bitmap. We try to allocate the block in the same cylinder group as the other blocks in the file.
- Performance: Better!
- Robustness: Now the free block bitmap isn't a single point of failure, there are independent free-list and inode structures per cylinder group
But that's not all. Does it make sense to let huge files take up entire cylinder groups?
No! For instance, imagine a directory d that's in
cylinder group 1. d has two files, crap.mp3 and
hello.txt. Suddenly crap.mp3 grows in size to
gigantic proportions and takes up the entire cylinder group. What happens
if hello.txt grows even by a tiny bit? Well, we have to go to
another cylinder group, causing a seek in the middle of a 2-block file! It
would be far better to cause the seek in the middle of the
crap.mp3 file, which, because it is big, will
already take a long time to read.
Thus, FFS tries to spread large files out across the disk! When a file goes above 40KB, and then at every megabyte thereafter, FFS switches cylinder groups. This generally leaves cylinder groups enough free space to work with.
Atomic Rename
 Say you have a
directory entry for the following file:
Say you have a
directory entry for the following file:
/home/Lei/thesis.doc
You now want to rename the file by using:
mv /home/Lei/thesis.doc /home/Lei/thesis.txt
 Just
do a simple change in the Filename in the directory entry. Filename=thesis.txt.
Just
do a simple change in the Filename in the directory entry. Filename=thesis.txt.
However, if we want to rename the file to a different directory [mv /home/lei/thesis.doc /shared/thesis.doc] what will happen then? We can create a duplicate Directory Entry, which points to /shared/ as the directory it belongs in. There is a problem with this though, this is a multi step operation!
There are 2 steps involved in coping/renaming a file between two different directories with directory entries.
- Add directory entry to new directory, including all block pointers
- Remove original directory entry
What happens if this operation crashes after step 1?
This will violate invariant 3, "No block belongs to more than 1 file"! It looks like two different files share blocks with one another.
Unix solves this issue with the concept of an inode, which separates metadata from directory entries. Now a directory entry can be thought of as the name and inode pointer. The following diagram is what may potentially happen during a rename to a new directory.
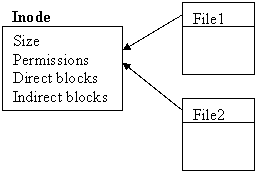
During a rename to a new directory our system crashes after step 1 (copy directory entry), the result is having 2 directories pointing to the same inode. This does not break the invariants, though, since the data blocks are still only pointed to by one file (one inode).
This capability, of having multiple links to a file, is explicitly
supported by Unix. We can add multiple links to an inode. These are
called "hard links"; we'll see next time why. Any writes made to the file
using one of its names can be read using another name. And "deleting" a
file -- removing a link from a directory to an inode -- doesn't remove the
data from disk until all the links are removed. This is why the
Unix system call for removing a file is called unlink and not
delete.
Mounting: (Page 445-447 of text)
A file system must be mounted before it can be available to processes on the system, similar to how a file must be opened before it is used.
Then the operating system mounts a file system it performs the following:
- It is given the name of the device and the mount point (the location
within the file structure where the file system is to be attached.)
Typically a mount point is an empty directory. For example, in UNIX a file system with user
U’s home directory can be mounted on the empty directory/home/U. We can then access a user’s directory via /home/<user name>. If we mount the filesystem under /users, we would then have to access the user’s directory via /user/<user name> - The file system verifies the mount contains a valid file system.
It asks the device driver to read the device directory, and verify that the directory has the expected format
- OS remembers that the file system has been mounted at the specified
mount point.
From now on, any accesses to the empty directory will "jump" automatically into the mounted file system. The mounted file system can also "jump" out, by following parent-directory links.
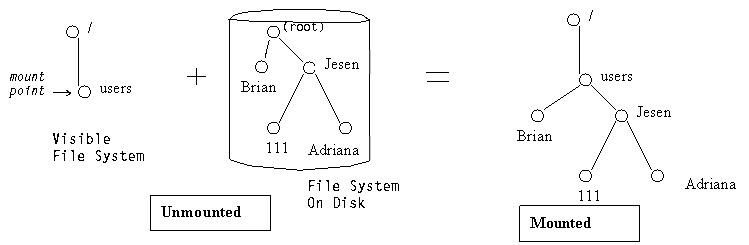
The following figure shows what a partition looks like after it is mounted:
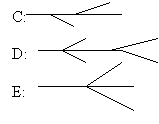
DOS uses drive letters. The file system is not a tree, but a forest: it has many roots. Mounts are restricted: When you mount a file system, it turns into a new drive letter.
The UNIX file system is tree-structured: there is a single root. All mounted file systems are accessible from the root, and mounts can appear anywhere in the tree.
- attaches file systems as branches to the root file system (can be mountd on any directory)
i. sets a flag in the inode for that directory which indicates that the directory is a mount point. A field points to an entry in the mount table, indicating which device is mounted there.
ii. Allows OS to traverse directory structure and switch among file systems as appropriate.
- system can be configured to mount file systems on startup
Disk Scheduling Algorithms
When there are several processes requesting a disk access (e.g. for a read or write), what order should they be served? Disk scheduling algorithms determine the order disk requests are processed, which can be a crucial factor to performance. The object is to minimize the seek time for/between each request.
First-Come-First-Served (FCFS) :
- Simply processes disk access requests in the order they arrive.
- Problem: Can be very slow. Requests for spaced-out regions of the disk may cause the read/write head to swing back and forth, causing longer seek times. For uniformly random files, the read/write head seeks 1/2 of the disk on average for each request. We could obtain better throughput if we processed groups of requests for areas of the disk that are adjacent or closer to each other: if proximity on disk influenced locality of reference.
Shortest-Seek-Time-First (SSTF): a.k.a. Shortest Job First (SJF):
- Chooses the request that will cause the shortest access the nearest position to the seek head first.
- Problem: Can cause starvation. A request for a part of the disk far away from the current position of the disk head may never get served.
[C]SCAN: (elevator scheduler) fairly good
- Seek across disk in one direction and serve all jobs in that path. Once the other end is reached, service the requests that are on the reverse direction. Minimizes amount of zig-zag, so there’s less seek time and therefore it has better performance. SCAN searches back and forth, like an elevator that goes up as far as it can, then down as far as it can. It provides unfair service, since blocks in the middle are more frequently serviced than blocks on the ends. C-SCAN, or circular scan, searches only in one direction, and is fair.
RAIDs (Redundant Array of Independent Disks)
A RAID is an architecture that employs multiple disk drives in a scheme that aims to maximize performance and/or minimize data loss. There are several types of RAID architectures, each with advantages and disadvantages with respect to one another.
The 2 extreme cases are described below:
RAID 0 (a.k.a. Striping)
In RAID 0, the different blocks of a file are spad out across multiple (N) disk drives.
- Performance: Very fast! Reads and Writes are N times faster because different blocks can be read/written concurrently.
- Robustness: No better! If one disk drive fails, then unrecoverable data loss has occurred.
- Efficiency: No different from a normal disk.
RAID 1 (a.k.a. Mirroring)
In RAID 1, each write goes to all disk drives in the array. Therefore, each disk drive’s contents are identical to each other, and there are N copies of the same data (where N = the number of disks drives in the array).
- Performance: Reads are N times faster, since you can read from N disks in parallel. Writes are nearly the same speed as with a system containing only 1 disk drive.
- Robustness: There are N copies of the same data, so the system can tolerate N-1 disk drive failures.
- Efficiency: Space utilization = 1 / N