RAID & file system robustness
The two main mechanisms for file system robustness are simplicity and replication. Two means of measuring robustness are mean time to failure (MTTF) and mean time to data loss (MTTDL). MTTF usually involves mechanical problems like a disk sector going bad, while MTTDL is the average time until data becomes unrecoverable. Replication and backups change the distance between mean time to failure and mean time to data loss. A very robust system has MTTDL >> MTTF.
Suppose we have exactly one disk, and we have a system with a very simple failure model: 1 disk, which will fail after exactly 1 year. (So its MTTF (mean time to failure) = 1 year, obviously!) The failure profile could be represented as below:
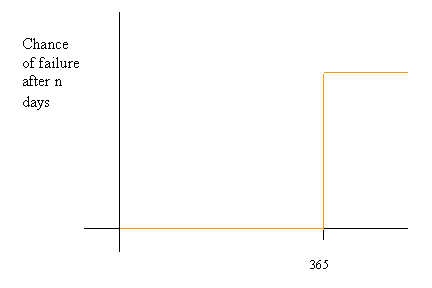
In reality, many disks have profiles similar to the one above: it is possible to predict with high accuracy when a disk will fail. This allows companies to set up a schedule to replace disks preemptively.
If we have no backups, and no redundancy on disk, then MTTF = MTTDL.
On the other hand, if we always have backups, and if they are easily and dependably accessible, then MTTDL is infinite.
RAID (Redundant Array of Independent Disks)
One way to improve file system robustness is to use RAID. RAID can also potentially improve performance by increasing bandwidth.
RAID 1 – mirroring
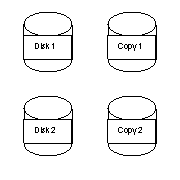
RAID 1 basically stores a copy of a disk's data on another disk. The robustness improvement depends on failure profile. If the disks have a failure profile like the unit step curve above, then failures are guaranteed to happen at an exact time. The disks are not independent of one another and there is no advantage to RAID 1 if we store and backup data starting at the same time (because both the disk and its backup will fail at the same time!) However, realistically, we are unable to predict the exact time when a disk will fail, and therefore, it is useful to keep a backup copy. Because there are two disks with the same data there's a performance improvement of N (the number of disks), but efficiency is only 50% since half the disk is wasted.
Is it possible to do better?
Other RAID levels:
|
Data |
Redundant Data |
RAID level and notes |
|
1 block |
1 block |
RAID 1 – can only tolerate one failure, overhead = 50% |
|
1 block |
5 blocks |
RAID 16 – can tolerate five failures, overhead = 80% |
|
2 blocks
|
1 block |
RAID 2 – the redundant data consists of a parity block, overhead = 30% |
|
5 blocks |
1 block |
RAID 4 – overhead = 17% |
RAID 2 uses a parity disk to recover lost data. A block on the parity disk contains B1 XOR B2 where B1 and B2 are corresponding blocks on the other two disks. If B1 were somehow lost, it can be recovered by finding B2 XOR <corresponding parity block>. A parity block is an example of error-correcting code. Error-correcting code requires n bits to encode from m bits of encoding. If f bits or less are lost from the m bit encoding, the original n-bit text can still be recovered.
RAID 4
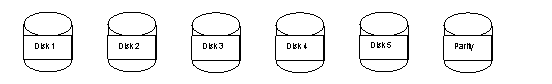

When using RAID 4, each disk has a size of S, but the operating system sees one (virtual) disk with a size 5S. The parity disk contains the XOR of the data on the corresponding blocks on the other five disks. Although this requires less overhead than RAID 1 or RAID 2, it is less robust since data could become unrecoverable if any two blocks that share a parity block are lost. Another problem is that if we want to write to block two of disk 4, we also need to read block two of every disk before writing to block two of the parity disk. While this does create additional processing and seeking, this can be simplified by saving the old data from disk 4 so that the other disks do not have to be read (e.g. Pnew = (Pold XOR B4,old) XOR B4,new). Than larger problem is that the parity disk must be written to for every write on any other disk—this means that the parity disk is used more and, therefore, will probably fail faster. This can be solved by striping the parity data across disks as in RAID 5. (RAID 5 also has the advantage of treating all disks the same, keeping them as independent as possible.)
Directory Links?
The general process of moving a subdirectory from one directory to another is the same as for a file. First, add a link from the new directory to the subdirectory; then, remove the link from the old directory to the subdirectory. This requires the "inode" level of indirection we introduced last lecture. For directories, we also must change the subdirectory's parent record to point at the new parent. (Different file systems will implement this in different ways, of course.)
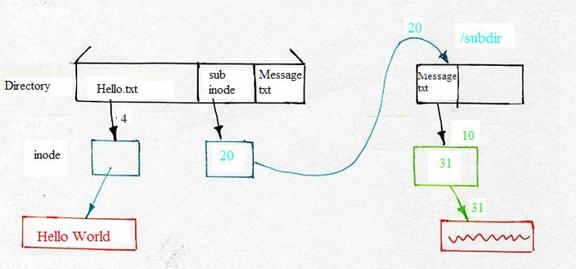
Besides allowing atomic file renames between directories, inodes gave us a new and interesting piece of functionality: namely, the ability to add links to a file -- to refer to a file inode from more than one directory. Question: Should we allow the user to add links to directories in the same way?
No! If we allow such links, it is possible to change the file
system structure into a loop, where a directory's child is also one
of its ancestors. For example, link("/subdir", "/subdir/x/y")
could result in:
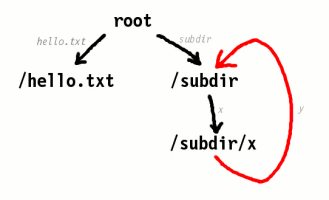
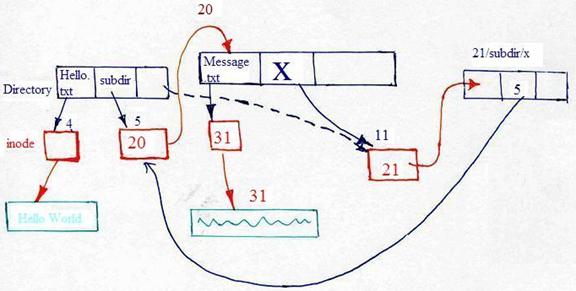
What's so bad about circular directory links? Well, they can seriously
confuse any program that's trying to walk the file system. It is much
easier to write a recovery program like fsck if you can assume
that the file system directory structure is a tree: that means that any
simple search, such as breadth-first search, will visit every directory
entry exactly once. The invariant being violated here is that every
directory has exactly one parent.
Although we cannot "link" a directory, is there any way to get a similar effect?
Luckily there is: By adding another layer of indirection – Symbolic Links
Symbolic Links
Symbolic links were not invented just to link directories. They are a separate feature from hard links, and very useful in many ways. But they do let us link to directories as well.
Symbolic links introduce links at the level of file names, rather than the lower-level concepts of disk blocks or inodes.
Advantages (+) and disadvantages (−) of sym links:
+ Can link to directories
+ Can link across file systems (A conventional link only works within a single file system)
− Dangling links: doesn't prevent the original file from being deleted
− Symbolic links can be circular, i.e. symlink("evil",
"evil"). This introduces a new failure mode; on Unix, an error
ELOOP. In order to prevent infinite recursion, the OS will
give up when it cannot find a file within a certain amount of
iterations.
What is a symbolic link? It's a new type of inode. So far, we've
talked about inodes that represent regular files, and inodes that
represent directories. Call these types REG and
DIR. Well, symbolic links introduce a new type, called
LNK. When the kernel looks up a file of type
LNK, it:
- Looks up the data blocks corresponding to the file.
- Reads that data.
- Interprets that data as a file name.
- Looks up that file name, and continues.
Thus, symbolic links are links at the namespace level, rather than the block level.
How does this allow links to directories? Well, a symbolic link from
one directory to another behaves to the user like a directory link; but on
the other hand, the fsck program won't get confused, because
those links have a different type. Fsck knows not to recurse
down into a symbolic link.
Example of difference between hard link and symbolic link:
Hard Link Symbolic Link
1. $ echo a > a.txt $ echo a > a.txt
2. $ ln a.txt b.txt $ ln -s a.txt b.txt
3. $ rm a.txt $ rm a.txt
4. $ echo z > a.txt $ echo z > a.txt
5. $ cat b.txt $ cat b.txt
6. a z
In the hard link case, the link is to an inode, which includes
all the data corresponding to a file. When we remove the
a.txt file (line 3), the inode lives on, attached to the name
b.txt. On the other hand, in the symbolic link case, the
link points to a file name that might or might not exist. When we
remove the a.txt file, the inode dies; and subsequent access
under the name b.txt would fail too.
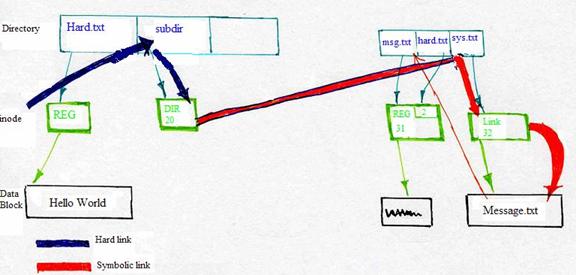
In hard link, when the OS links a.txt to b.txt, a different block is allocated for b.txt with character "a" written to it. When the OS does "echo z > a.txt" after removing a.txt, b.txt is not affected since the two files reside in different blocks and hard links only manipulate actual blocks. As a result, we see an output of "a" rather than "z."
However, in symbolic link, both a.txt and b.txt is pointed to block of a.txt such that a change of a.txt will affect b.txt as well. As a result, we see the output of "z," as shown in the example.
Kernel Operations for File Systems:
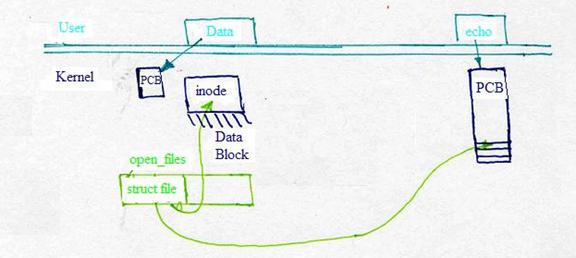
The kernel represents the offset of the file by the last byte that it has read, and it determines which block to read next by calculating block index ==> file offset / block size. In addition, the inode of a file keeps track of the blocks that the file is contained in by storing an array of direct block numbers + indirect block pointers.
During the lecture, we discussed the kernel operation of reading a file. What should the interface be? We discussed the consequences of one choice:
read(filename, offset, data, size)
Problems are many. (−) No obvious cache of data; (−) Problems with multiple writes to same file; (&minus) Must redo access control checks & file lookup on every file operation
struct file
Read Write Sync Close (function pointers)

VFS Layer
Virtual File System Layer
open() ==> open() inode pointer
read() ==> read() file operator
In addition, we also discussed the actual Linux File Systems:
FAT, VFAT – Windows Partitions
ext2, ext3 - Linux native (FFS- like)
Joliet - CD-ROM
Procfs - make system information available through the file system layer -- no stable storage!
To close, we discussed one of the many implementations of
the read function, this one for /proc/memory:
read(...) {
char buf[];
sprintf(buf, "%d\n", free_mem);
...
copy_to_user(...);
}