CS 111 – Spring 2005
Synchronization & Deadlock Notes
Lecture 8 – April 27, 2005
Authors: Kimbo Djakaria, Cory Weng, Brian Leung, Leslie Choong
Locks
Where do we put locks in a program? And how many locks should there be? These questions have motivated the designs of several different locks and synchronization mechanisms.
The most basic choice is between having few coarse-grained locks and many fine-grained locks. To summarize the advantages and disadvantages:
Few coarse-grained locks |
+ Correctness is easier (with only one lock, there's less
chance of grabbing the wrong lock, and less risk of deadlock) − Performance is lower (not much concurrency) |
 | |
Many fine-grained locks |
+ Good concurrency/parallelism = good performance − Correctness is harder (it's easier to make a mistake and forget to grab the lock required to access a resource) − Higher overhead from having many locks |
Let's dig a little deeper. Say that we have two
programs, P1 and P2, that are trying to write 1 and
2 characters into a buffer. The buffer should be filled up
with 1s and 2s from left to right, but neither
process should never overwrite a buffer slot already used by the other.
(See WeensyOS 2.) We want the buffer to
contain the right number of ones and twos, i.e.
| 1 | 1 | 2 | 2 | |
 |
|
|||
| P1 last wrote here | P2 last wrote here |
We don't want a race condition to occur where one of these processes overwrite the other one's data.
| 1 | 2 | |||
|
||||
| P1 last wrote here P2 last wrote here |
The simplest way to guarantee synchronization is
to put each of the processes entirely in its own critical section,
so one process runs into completion before the other one starts. This
strategy is very coarse-grained: we have just one lock, which essentially
covers all system resources. This solution is pretty easy to
program! Each process can simply acquire the single lock at the beginning,
then release it at the end. (Or, even easier, we could wait for the first
process to exit() before launching the second process.) On
the other hand, there's no concurrency in the system!
To achieve greater concurrency -- and often better performance -- we can move to finer-grained locks. Rather than protecting all system resources, each fine-grained lock will protect a single resource, or a small number of them. Rather than holding a lock for a long time (as above, where a process holds the whole-system lock for as long as it runs), each process will hold this lock for as little time as possible while still providing protection. In this example, we might have a lock that protects buffer accesses; each process grabs the lock, writes a single character into the buffer, releases the lock, and repeats.
The advantage of this approach is concurrency (and therefore performance). In a coarse-grained locking system, a process will often hold a lock that protects a resource it doesn't access. For example, the coarse-grained lock above, which covers all system resources, protects the network as well as the buffer; but neither P1 nor P2 accesses the network! A process P3 that wants to access the network has to wait for P1/P2 to release the lock first, even though it could safely run in parallel with either of them. This prevents meaningful concurrency. In a fine-grained locking system, processes aim to hold minimal sets of locks. In our example, P1/P2's lock covers just the buffer, not the network, so P3 could access the network in parallel with P1/P2 accessing the buffer. There are two disadvantages. First, overhead. There are many more locks in the system, and each lock takes some space; and there are many more lock acquire/release operations, each of which takes some time. And second, programmability. With many locks, each protecting a handful of resources, it's a lot harder to tell which locks are needed to safely execute some operation; it's easy to forget a lock or cause a deadlock.
The reason people have invented so many different synchronization objects is to try to find a sweet spot on the continuum where you have fine-grained locking so that performance is high but easy enough to program so mistakes can be avoided.
Different kinds of locks:
1. Mutex (Mutual Exclusion)
The mutex is the simplest kind of lock. It has two operations:
typedef struct mutex {
int l;
} mutex_t;
1. acquire(mutex_t *m) {
while (m->l == 1)
sleep & try again;
m->l = 1; /* atomic with the 'm->l == 1' check above */
}
2. release(mutex_t *m) {
m->l = 0;
}
How coarsely-grained or finely-grained is a mutex? Where does Mutex lie on the spectrum? One can have many mutexes on a program. Mutex is the mechanism used to implement all other functions of synchronization in a program. If you have one mutex protecting an entire program, then it is coarse-grained locking. If you have many mutex, say, one per integer in your program that you might want to read or write, then you have fine-grained locking.
Block Synchronization (Java synch)
People have used programming languages to attempt to hide these acquire and release operation. One of the current ones is called block synchronization and this is the kind of synchronization that Java has. Every object has a secret mutex.
Object o {
mutex lock; // this is hidden
int i;
void inc() {
synchronized (this) {
// everything in this section is atomic
// with respect to other "synchronized" blocks
// on this object
i++;
}
}
}
What does the synchronized section compile to in Java?
Object o {
mutex lock; // this is hidden
int i;
void inc() {
// synchronized (this) {
lock.acquire();
i++;
lock.release();
// }
}
}
Why wouldn't it be easier to just call acquire and release directly? Because you might forget to release. This kind of error actually happens all the time.
Let's change the definition of inc(). inc() is going to send an error if i is negative; we are only supposed to increment if i is positive.
Object o {
mutex lock; // this is hidden
int i;
int inc() {
lock.acquire();
if (i < 0)
return -1;
i++;
lock.release();
return 0;
}
}
Where is the error?
If i is negative, the function
returns without releasing the lock. But if we get replace the explicit
acquire and release with a synchronized statement, the
compiler will be smart enough to see that when we return -1
inside the if statement, the lock should be released.
Thus, lock synchronization is a way to avoid common error
condition.
Are these synchronized locks fine-grained or coarse-grained?
In Java, every object have a lock, therefore it is fine-grained.
Are there any costs to that?
Yes. If every object has a lock, then every object has to initialize the lock, create the lock, and create space for the lock, which in the end will lead to overhead.
Recursive Mutex
What happens when we have this?
synchronized (this) {
synchronized (this) {
i++;
}
}
Deadlock occurs because the inner
synchronized can never obtain the lock that the outer
synchronized has already acquired. The solution to this
problem is a recursive mutex, which allows the same thread to lock
multiple times.
Implementation:
typedef struct rmutex {
int l;
pid_t pid;
} rmutex_t;
pid_t getpid(); // system call returns current thread's ID
void acquire(rmutex_t *m) {
while (m->l > 0 && m->pid != getpid())
sleep and try again;
m->l++; // atomic with "m->l > 0" check above
m->pid = getpid();
}
void release(rmutex_t *m) {
m->l--;
}
Any lock that has already been acquired has an
l value greater than 0. The acquire function
takes in a lock, and checks if it has already been acquired. If it has,
then it checks m->pid, the PID value currently associated
with the rmutex. If the PID matches the PID of the process trying to
obtain the lock, the process is allowed to acquire the lock again.
Thus, a thread that owns the lock for an object can enter another
synchronized block for the same object. Release simply
decrements l, and in a recursive mutex, the number of acquires
equals the number of releases.
Read/Write locks
One common use for locking is to ensure that some object doesn't change while we read it. For instance, say we wanted to count the number of lines in a file. We might lock that file as we counted to ensure that no one could change the file as we worked. If we used a conventional mutex, would there be a performance/concurrency problem? Absolutely: only one process could read the file at a time. This seems a little overprotective (coarse-grained), since the line-counting process isn't changing the file!
To solve this problem, we can introduce a read/write lock. This
kind of lock has four operations, not two. The
acquire_read and release_read operations acquire
the lock for reading the object, while the
acquire_write and release_write operations
acquire it for writing. However, multiple processes can be in a
"read" critical section simultaneously. That is, "read" critical
sections are non-exclusive. But "write" critical sections are exclusive
both with each other, and with "read" critical sections: if you're writing
the object, no one else can be writing or reading it.
We can implement a read/write lock by using a conventional mutex. (A recursive mutex would be possible too.)
typedef struct rwlock {
mutex_t m;
int rcount;
} rwlock_t;
acquire_read(rwlock_t *rw) {
acquire(&rw->m);
rw->rcount++;
release(&rw->m);
}
release_read(rwlock_t *rw) {
acquire(&rw->m);
rw->rcount--;
release(&rw->m);
}
acquire_write(rwlock_t *rw) {
while (1) {
acquire(&rw->m);
if (rw->rcount == 0)
// no one is reading, we're done
return;
// otherwise, try again
release(&rw->m);
}
}
release_write(rwlock_t *rw) {
release(&rw->m);
}
Acquiring and releasing a read lock is straightforward, and simply increments or decrements rcount. However, acquiring a write lock is only possible if rcount == 0, in other words, if no other thread has a read or write lock on the object.
Read/write locks are most useful in the following situations:
1) In applications where it is easy to identify which threads only read shared data and which threads only write shared data.
2) In applications that have more readers than writers. Although read/write locks may require more overhead to establish than mutex locks, this is compensated by the increased concurrency of allowing multiple simultaneous readers.
Condition Variables
Sometimes a process wants to wait for a condition other than
mutual exclusion. For example, say that a process wants to lock variable
i once that variable reaches a value >= 2. How can we
possibly implement this with mutual exclusion?? The obvious way is just to
busy-wait on the condition:
int i;
mutex_t i_mutex;
cond_t i_geq_2_cond;
...
acquire(&i_mutex);
while (!(i >= 2)) { // give another process a chance to run,
// so it can maybe set i to 2 or more
release(&i_mutex);
acquire(&i_mutex);
}
// Now we hold i_mutex, and i >= 2.
...
But like all busy waiting this has high overhead.
The condition variable synchronization object was designed for
this application. A condition variable is associated with some
mutual-exclusion lock; there can be many condition variables per lock. The
variable represents some state of the program -- for example, "i >=
2". A process that wants to wait for this condition does the
following:
int i;
mutex_t i_mutex;
cond_t i_geq_2_cond;
...
acquire(&i_mutex);
while (!(i >= 2))
cond_wait(&i_geq_2_cond, &i_mutex);
// Now we hold i_mutex, and i >= 2.
...
Now, the system will put us to sleep until some program changes the
state so that i is 2 or more. But how does the OS detect this
state change? It relies on the application! Application programs must
signal the condition variable when they might have made the
condition true. (The signal operation is also sometimes called
"raise".) For example, the operation to increment i must be
written like this:
void inc_i() {
acquire(&i_mutex);
i++;
if (i >= 2)
cond_signal(&i_geq_2_cond);
release(&i_mutex);
}
(This signalling protocol is pretty precise; instead, the process might signal the condition variable on every increment. The point is that we must signal the condition variable whenever there's any chance that the condition has become true.)
Here's how these operations are implemented.
void cond_wait(cond_t *cond, mutex_t *m) {
release(m);
sleep until someone calls cond_signal(cond);
// NB: The sleep operation occurs atomically with
// the release(m) operation, so there is no race
// condition.
acquire(m);
}
void cond_signal(cond_t *cond) {
wake up any processes waiting on cond_wait(cond);
// Might also wake up >= 1 waiter.
}
Semaphores:
Definition: An integer variable that, apart from initialization, is accessed only through two standard operations: acquire( ) and release( ).
Background: acquire( ) and release( ) used to be called P and V, Dutch for proberen "to test" and verhogen "to increment".
Usage: A lock (L) is initialized to the number of resources (corresponding to that lock) that is available. Then, acquire( ) checks to see if L is greater than 0, if it is not, then no resouces of this type is available. If it is greater than 0, then a resource is available and we decrement count of L. On release(L), L is incremented (to show that another one of these resources are available. If L is initialized to 1, then the lock is a mutual exclusion lock (only one process may grab it at a time). When more than one process can hold the lock ( L > 1 ) at a time, then it is called a "weak mutual exclusion".
Code: acquire(L):
if (L > 0)
L--;
return;
else
sleep and try again
release(L):
L++;
if (L > 0)
wake up 1 or more waiting processes
Monitors:
Definition: A user defined type in languages such as Java. Only one process may access a function inside of a monitor at one time. Therefore, mutual exclusion is provided without all the errors that may occur in other synchronization methods such as Semaphores. (Block synchronization is 1 lock per object which is fine-grained locking. Monitors have 1 lock per class which is coarse-grained locking.)
Code: Monitor {
entry inc(i) {
i++;
}
}
Monitor.inc(i) and Monitor.inc(j) can not be done at the same time.
Barriers:
Definition: A thread synchronization mechanism that allows several threads to run for a period of time but then forces all threads to wait until all have reached a certain point.
Usage: Say we want to do M1 X M2 + M3 X M4 + M5 X M6 where M is a
matrix. We can parse the work to three different processes where:
P1: M1 X M2
P2: M3 X M4
P3: M5 X M6
Then we can have P1 add up the results from the work done by each one of these threads. In this case, we can block at a barrier (b) until all three have done their work and then have P1 execute the addition.
Code: barrier(b) {
wait until everyone is at barrier b
continue
}
This needs to be given to each one of the processes.
Wait-Free/Lock-Free Synchronization:
Definition: This is one of the most advanced methods of synchronization. We use atomic instructions and/or clever data structure design to achieve safe synchronization without locking.
Example:
Consider a function to increment a variable i. With locking,
it would look something like this:
void inc(int *i, mutex_t *m) {
acquire(m);
(*i)++;
release(m);
}
But many architectures, including the x86, provide an instruction that provides the following semantics.
void compare_and_swap(int *addr, int old, int new) {
// x86 instruction "cmpxchg" is very similar
// All this is implemented as one atomic section:
if (*a == old) {
*a = new;
return 1;
} else
return 0;
}
Using compare_and_swap, we can implement inc
without a lock:
void inc(int *i) {
int old;
do {
old = *i;
} while (compare_and_swap(i, old, old + 1) == 0);
}
Since there's no lock here -- and, thus, no need to go to sleep and wait for the lock to be released -- this is called wait-free or lock-free increment.
Example 2: Wait Free Queue:
If we have a circular queue and two pointers, one pointing to the head of the queue and the other pointing to the tail of the queue, then we have a data structure that allows reading and writing to the queue at the same time -- as long as there's exactly one reader and one writer. For more, see the last example in this code.
Deadlock
Deadlock occurs when the system halts forever -- with no further progress possible -- because processes are waiting for locks that will never be released. This is a big problem when we are trying to synchronize processes. On one hand we want to lock down specific resources so that other processes cannot create some undefined behavior, but by locking down a resource we create the possibility that other processes will be stuck waiting for a lock that the owner of the lock may unintentionally never release.
Let's try this thought experiment:
We are using non-recursive locks…
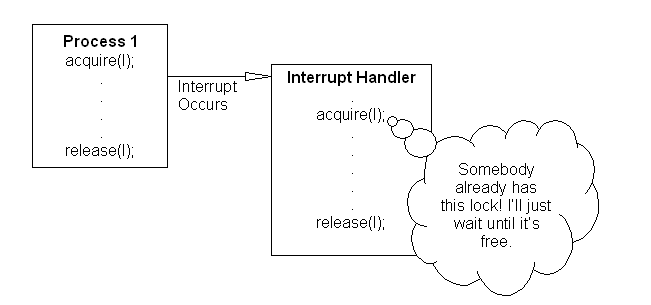
If this were to occur, the system would be deadlocked because we would never switch out of the interrupt handler, and therefore spend eternity and more waiting for a lock that Process 1 will never have a chance to release.
Let's try another thought experiment:

Here we have a different kind of problem. Since processes can be preempted anywhere it is possible that we could switch out from P1 after acquiring lock a, then P2 acquires lock b. Then P1 is stuck waiting for P2 to release lock b while P2 is stuck waiting for P1 to release lock a. Both processes are stuck and will churn away forever, fruitlessly hoping that one day they will find the right lock to call their own.
There are 4 conditions necessary for deadlock to occur:
Four Conditions necessary for Deadlock
- Mutual exclusion
- Hold & Wait (if you cannot get a lock, wait)
- No preemption (cannot steal others locks)
- Circular Wait (P1 waits for P2 which is waiting for P1)
It is easiest to prevent Number 1 (recursive locking?) and Number 4 (careful programming).
Lock Ordering
A technique called Lock Ordering can be used to help prevent circular waits. By assigning a total order to all the locks in a system, then circular deadlocks can be prevented.
acquire(l) is allowed iff (l.order > any other acquired locks order);
Try this out for yourself and reorder the situation above so that circular deadlock cannot occur. (you can order it however you like a,b,…. or b,a,….)
Hey, Why don't we just break deadlocks?
Is it possible to have a built-in Operating System Deadlock Detector? If so, what would the detector do if it found a deadlock? Should it kill the process? Should it send a scathing email to the maintainer of that program/process reprimanding them for their shoddy work?
While it is possible to have a deadlock detector, it seems a little impractical. We would be adding an extra layer that checked for deadlocks every so often and this can lead to overhead. Secondly, what exactly would the detector do? If it did kill a process, undefined behavior may begin to occur and who knows what would happen next. Programmers need to be aware of the issues and dangers involving synchronization and deadlocks and program defensively and wisely in order to prevent them. However, deadlock detection can be a useful part of that defensive programming. A system that periodically checks for deadlock, and if it finds it takes some aggressive action (like rebooting), can help a system survive much longer without human intervention.
A deadlock preventor can make more sense. For example, the Unix
operating system supports read/write locks that protect arbitrary regions
of files (using the fcntl system call, with operation
F_SETLK/F_SETLKW). Deadlock is a definite possibility! Unix
prevents it by causing the acquire attempt that would cause deadlock to
fail, with error EDEADLK.