CS 111
Scribe Notes for 5/4/2005
By Wai Chan, Eusden Shing , Jonathan
Hung, Zhichao Huang
Operating System Privilege: Protection and Isolation
Here's a picture of the physical memory space of a machine with 256 megabytes of memory. Those memory bytes are accessed by addresses, which range linearly from address 0 to address 0xFFFFFFF (that is, 228 − 1, or 256 MB − 1).
 | |
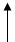 | |
| 0 | 256 MB − 1 |
The operating system places process code and data into physical memory. The exact locations are constrained, in some cases, by the architecture, which maps certain physical memory locations to particular devices, such as the screen. Here, for example, is how memory is allocated in WeensyOS 1's PasswdOS:
We'd like to isolate process so that they will not interact improperly. For example, in WeensyOS 1, the printer can access or change the checker's data memory or program memory. We want to prevent this. But how?
We'll assume that a part of the operating system -- the operating system kernel -- has special privilege, but that applications do not. Our goal for the day is to figure out a sufficient set of architectural operations that must require special privilege -- that only the kernel can do -- in order to keep the processes correctly isolated.
Memory
Management
The first step is memory itself. We want to isolate the processes' memory spaces, so that each process can access only its own memory. The different processes' memory spaces must be isolated from each other, and from the kernel. In PasswdOS, we want the two processes to experience these memory layouts. (This is not exactly the PasswdOS from WeensyOS 1; instead, it's an abstracted PasswdOS that has a kernel. For example, we've left off the pipe.)
Printer:
| Not accessible | Accessible | Not accessible | |
| 0 | 1MB | 2MB | 256MB−1 |
Checker:
| Not accessible | Accessible | Not accessible | |
| 0 | 2MB | 3MB | 256MB−1 |
Segments
Notice that the accessible portions of memory are contiguous linear subranges of the complete memory space. One natural way to enforce isolation, then, would be segment protection, where the processor's access to memory is potentially limited to one or more linear subranges of physical memory.
For instance, say our architecture let us specify a segment base and segment length. An access to memory address M will only be allowed when base ≤ M < base+length. If we set the bases and lengths like this, the printer and checker will be isolated from one another:
|
|
Printer |
Checker |
|
SEGMENT BASE |
1MB |
2MB |
|
SEGMENT LENGTH |
1MB |
1MB |
In fact, x86 processors support this kind of protection. The earliest x86 processors (the 8086 model) had segment registers, but not segment-based memory protection, which was introduced with the 80286. 8086 segments allowed that 16-bit architecture to access 220, rather than 216, bytes at a time; they were not designed for privilege or isolation. Segments can cause annoying programming issues since programmers have to remember to change segment registers themselves. But they do work!
x86 segmentation uses a set of segment registers, namely
%cs, %ds, %es, %fs,
and %gs.
The processor uses the %cs "code segment" when executing code,
and the %ds "data segment" when reading or writing data. If
%cs and %ds have different values, then a process
might be unable to read or modify its own code! The other segment
registers may be used to read or write data, but in modern OSes they are
generally not used.
A segment register doesn't contain a base and length directly; instead, it is an offset into a global descriptor table or GDT, which is where the base and length can be found. For instance, this GDT has separate entries for the printer's segment and the checker's segment:
GDT (Global Descriptor Table)
|
Null |
|
Base
Offset length
Privilege |
|
Base
Offset length
Privilege |
8 byte
![]() Privilege: can be
0, 1, 2, 3 depend on the user
Privilege: can be
0, 1, 2, 3 depend on the user
![]() Printer
Printer
Checker
Besides base and length, a segment descriptor contains an offset, which can be used for simple virtual address mappings, and a privilege level. This is a number between 0 and 3, where 0 is "most privileged" (the kernel) and 3 is "least privileged" (user-level applications like the printer and the checker). In most cases, the processor's current privilege level (CPL) is taken from its code segment's privilege level field.
Segments also contain flags, which can, for example, prevent the processor from writing to a segment or from executing code in that segment.
Remember that all these checks are implemented by the hardware! The OS's job is just to set up the right structures. On memory access using a certain segment S, the machine checks if address is less than the length of the segment. If it is not, a fault is executed. Otherwise, the physical address is calculated by adding the address and the offset of the segment.
So what operations must be privileged here?
- Setting segment registers. If the printer could arbitrarily set its data segment register to equal the checker's data segment, then it could edit the checker's data! So the architecture validates all segment register changes.
- Modifying the GDT. If the printer could modify the GDT, then it could clearly grant itself more privilege. To avoid this, the OS must store the GDT in kernel memory, inaccessible to either printer or checker.
- Setting the GDT pointer. The hardware's current GDT is stored
in a special register, and loaded by the
lgdtinstruction. Clearly this instruction must be privileged, or the printer could just load a new GDT granting itself all the privilege it wants. So the architecture only allows thelgdtinstruction in "kernel mode" (at current privilege level 0).
Paging
So segmentation can be used to provide isolation, but it's also pretty hard to use. For example, it requires that the operating system allocate contiguous physical memory for each process (or, at best, a handful of contiguous ranges). This can lead to fragmentation problems and generally makes the OS's job harder. How can we do better?
Current architectures and OSes generally impose
isolation, and manage their memory spaces, using paging. In paging,
memory is divided into equally sized chunks called pages that are 2x bytes
long. On an x86: x=12 and each
page is 4KB.
The hardware implements a page table function PT that enforces protection on the level of individual pages. This is much more flexible than segmentation, since the OS can, for example, provide access to every other page of memory! (However, only segmentation can grant access to units smaller than a page.) When a process accesses an address, the processor looks up that address in the page table. If the page table indicates that the process shouldn't have access to the address, a page fault occurs, which generally kills the program. (In Unix, page faults generally show up as segmentation violation signals.)
Virtual
Addresses
The page table function also maps virtual memory addresses to physical addresses. When an instruction attempts to access a memory location A, the hardware actually converts that address from virtual (A) to physical (PT(A)) before accessing physical memory. This is a more flexible version of the "offset" field in the segment descriptors. We'll deal more with virtual memory later.
The page table works on the granularity of pages. Every address A is broken into two parts, the page number PN(A) and the page offset PO(A), where A = PN(A)*212 + PO(A) and 0 ≤ PO(A) < 212. (Again, 212 is the normal x86 page size.) The page table's virtual address mapping changes page numbers, but not page offsets. That means that page table entries don't need to map addresses' 12 lower-order bits.
x86 Page
Tables
How does the OS implement a given PT function? A page table is the data structure defining the PT function. Different architectures have different page table structures, and some architectures don't implement a page table at all. (Instead, the OS must implement a page table, and use special instructions to populate the processor's PT function.) We'll talk about the x86's version, a two-level page table.
The x86's %cr3 register points to the current page
directory. This page directory points to second-level page table
pages; the combination of page directory and page table pages
implements the PT function. When the application accesses a memory
address, the CPU essentially walks the page directory and page table pages
to find out whether the access is OK. (Of course, it speeds up this
process by caching recent addresses.)
The OS installs a new page table by executing the lcr3
instruction, which loads a physical address into %cr3. Why
physical? Because the processor doesn't know how to translate virtual
addresses until it knows the page table's physical address.
How does the CPU look up a virtual address and check its protection? The most significant 10 bits (bit 31 to bit 22) of a virtual 32-bit address determines the index into the page directory. The page directory itself is the size of a page and has 210 entries, each of which is 4 bytes long. Each entry in the page directory contains a physical address to the corresponding page table page.
The next 10 bits (bit 21 to bit 12) of the virtual
address determines the index into the page table page. The page table page
is also the size of a page. The
page table page has 210 entries, each of which is 4 Bytes. The
most significant 20 bits of a page table entry contains the most
significant bits of the physical address.
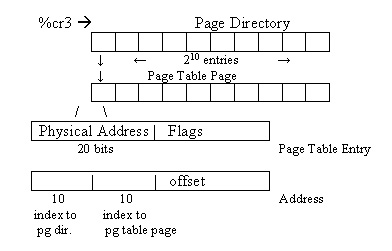
What does the hardware do when it is given the
instruction "movl 0x014200000C %eax", where the
first ten bits are equal to 5, the next ten bits are equal to 32, and the
last twelve bits is equal to 12?
- Access the 5th entry in the page directory -- that is, the word at
address
%cr3+ 5*4. - Use this entry to find PTA, the physical address of the relevant page table page. (If the entry indicates that there is no such physical address, or that the currently-running code doesn't have privilege to access this page table page, then the CPU will cause a page fault.)
- Access the 32nd entry in the page table page -- that is, the word at address PTA + 32*4.
- Use this entry to find PA, the physical address of the relevant data page. (Again, if the entry indicates that there is no such physical address, or that the currently-running code doesn't have privilege to access this page, then the CPU will cause a page fault.)
- Add the offset, 12, to PA to get the physical address to access.
The page table is basically an implementation of a hash table. Walking the page table every instruction is slow, so the processor uses a hardware cache called translation lookaside buffer (TLB) to store recently-accessed page table entries. If we change the page table, we must flush this cache.
Why 2 levels? If we used a one-level page table, with a 20-bit index, the resulting table would use a total of about 8MB, even if only 1 page was accessible. But with two levels, only two pages (8KB) need to be allocated to make 1 page accessible: one page directory and one page table page. The rest of the page directory can be marked empty.
Page Table Entry Flags

The
least significant 12 bits of a page table entry are flags defining the state of
the page to which the page table entry points.
For example:
P = 0: address illegal
W = 0: address is read-only
U = 0: only privileged code can access
These bits are how the page table implements protection.
Page table formats:
2
level (x86)
1
level, 3 level, 4level
Software
page table (Alpha)
(OS decided how to handle TLB
misses)
Inverted page table
(PowerPC)
(Store physical-to-virtual mappings instead of
virtual-to-physical)
While segmentation provides only isolation of process memory, paging provides isolation and flexible sharing. If two different processes need to access the same page, copying the page byte by byte so that each process can have its own copy can be slow; but if the data is read-only, only a pointer (the page table entry) needs to be copied. This is also known as copy on write; we'll see more later.
OK, given all this, what page table operations must be privileged to allow processes to be isolated?
- Setting the page directory register (
%cr3) must be privileged for the same reason that segment descriptors must be privileged. - Modifying the page table directly. If the printer could modify the page table, then it could clearly grant itself more privilege. To avoid this, the OS must store page table pages in kernel memory, inaccessible to either printer or checker.
How can we do a system call?
User-level processes communicate with the kernel
through system calls, which are examples of context switches.
These act like normal function calls, except that they change privilege
levels: the function is executed by privileged kernel code, although
the caller was unprivileged.
Changing privilege levels makes system calls potentially dangerous.
Applications shouldn't be able to cause the kernel to do anything
inappropriate. That means that, for example, applications shouldn't be
able to jump into the middle of a kernel function.
We need a way to jump from user space to privileged kernel space without
compromising isolation.
Therefore, kernel space
should only be entered through defined entry points. Steps for jumping into kernel space:
- save current state
- assume privilege
- jump to a kernel
defined location
This is done by using a trap: a software initiated interrupt. The kernel defines an interrupt descriptor table (IDT) that defines which traps are available, and which traps may be called by unprivileged code. Each IDT entry contains an instruction pointer, a stack pointer, and segment registers, which together define what code should execute when the interrupt/trap happens. It also contains a privilege level, which says whether applications can call the trap.
Example: System call in
WeensyOS
Application Assembly Code: int $48
What
the hardware does:
Looks
up interrupt 48 in IDT
Assuming IDT entry
allows int $48 from applications:
Jumps
to kernel
Assumes
privilege
Pushes application
CPU state onto the kernel stack
Starts running at the
EIP specified in the IDT
Once the kernel is done processing the system call...
Kernel Assembly Code: iret (returns
from interrupt)
What the hardware does:
Pop
CPU state from stack
Release
privilege
Return
to user process
So now which of these operations must be privileged to preserve process isolation?
- Setting the interrupt descriptor table (
lidtinstruction). - Modifying the IDT directly. As with the GDT and the page table, the IDT must be in kernel memory.
I/O
device access
Finally, let's consider the mechanisms by which applications can talk to hardware devices, such as disks. Hardware devices often have more-or-less direct access into the machine's memory; you can tell a disk, for example, to "read sector 29 and put the result at address 0x10000". But for direct memory access, hardware devices generally act like they have privilege! Sometimes a device uses physical addresses (avoiding all isolation provided by segmentation and paging); sometimes it uses virtual addresses, but with kernel privilege. So can we let applications access hardware directly? Clearly not! An application would be able to do anything it wanted by writing bad stuff to the disk, then asking the disk to load it at an arbitrary physical address.
This adds a couple more privileged operations to our list.
- There are CPU flags that determine whether or not a process has I/O
privilege (whether it can access hardware devices directly). On the x86
these include the I/O privilege level (IOPL) in the
eflagsregister. Changing these flags must require kernel privilege.
Of course, it's safe for the kernel to access hardware on behalf of a user-level program, as long as it carefully checks the arguments!
Other
privileges
We haven't exhausted the list of privileged operations, but we've listed many of the most important ones. Here are a handful of others:
- The x86 has flags that control low-level processor status, such as turning paging on and off. Changing those flags must require privilege.
- Turning interrupts on and off requires privilege.
- ...
This ends the lecture.