What’s happening in operating systems?
Drivers of operating systems research
- New hardware capabilities
- New applications
- New threats
- New goals
Frictions for operating systems research
- Backward compatibility with massive installed base
- New applications require huge infrastructure
- Community dynamics
Submissions to a recent OS conference
| Topic | Count |
|---|---|
| Distributed systems | 87 |
| Operating systems | 72 |
| Cloud computing | 71 |
| File and storage systems | 60 |
| Scalability | 50 |
| Security | 40 |
| Fault tolerance | 35 |
| Databases and analytics | 34 |
| Reliability | 31 |
| Parallel systems | 30 |
| Data centers | 29 |
| Networking | 28 |
| System support for machine learning | 28 |
| Parallel data processing | 24 |
| Programming languages | 24 |
| Measurement and analysis | 19 |
| System management | 19 |
| Virtualization | 19 |
| Verification | 18 |
| Debugging | 16 |
| Computer architecture | 15 |
| Graph processing | 15 |
| Privacy | 14 |
| Dependability | 12 |
| Deployment experience | 12 |
| Edge computing | 10 |
| Embedded systems | 10 |
| Energy and power management | 8 |
| Web systems | 7 |
| Workload characterization | 6 |
| Middlebox systems | 5 |
| Internet of things | 4 |
| Content distribution networks | 3 |
| Mobile and wireless computing | 3 |
| Multimedia systems | 2 |
Submissions to an earlier OS conference
| Topic | Count | Acceptances |
|---|---|---|
| Distributed systems | 94 | 15 (16.0%) |
| Operating systems | 56 | 14 (25.0%) |
| Cloud computing | 56 | 11 (19.6%) |
| File and storage systems | 53 | 9 (17.0%) |
| Systems aspects of big data | 45 | 5 (11.1%) |
| Datacenters | 40 | 10 (25.0%) |
| Analytics and databases | 37 | 3 (8.1%) |
| Security | 32 | 10 (31.3%) |
| Measurement and analysis | 26 | 6 (23.1%) |
| Dependability | 25 | 6 (24.0%) |
| Networking | 25 | 7 (28.0%) |
| Programming languages | 21 | 3 (14.3%) |
| Computer architecture | 19 | 4 (21.1%) |
| System management | 19 | 4 (21.1%) |
| Virtualization | 15 | 4 (26.7%) |
| Graph processing | 13 | 1 (7.7%) |
| Mobile computing | 12 | 0 (0.0%) |
| Embedded systems | 11 | 1 (9.1%) |
| Green computing | 3 | 0 (0.0%) |
Submissions to an earlier OS conference
| Topic | Count | Acceptances |
|---|---|---|
| Distributed systems | 99 | 22 (22.2%) |
| Cloud computing | 73 | 20 (27.4%) |
| Operating systems | 64 | 8 (12.5%) |
| File and storage systems | 56 | 10 (17.9%) |
| Data centers | 45 | 13 (28.9%) |
| Security | 45 | 8 (17.8%) |
| Scalability | 44 | 5 (11.4%) |
| Databases and analytics | 43 | 7 (16.3%) |
| Parallel data processing | 40 | 8 (20.0%) |
| Fault tolerance | 39 | 5 (12.8%) |
| Reliability | 27 | 7 (25.9%) |
| System support for machine learning | 25 | 6 (24.0%) |
| Networking | 24 | 3 (12.5%) |
| Programming languages | 24 | 4 (16.7%) |
| Parallel systems | 22 | 3 (13.6%) |
| Virtualization | 22 | 2 (9.1%) |
| Computer architecture | 21 | 3 (14.3%) |
| Measurement and analysis | 21 | 6 (28.6%) |
| Debugging | 15 | 6 (40.0%) |
| Privacy | 15 | 3 (20.0%) |
| Graph processing | 14 | 2 (14.3%) |
| Dependability | 12 | 3 (25.0%) |
| System management | 10 | 1 (10.0%) |
| Internet of things | 9 | 1 (11.1%) |
| Verification | 9 | 3 (33.3%) |
| Edge computing | 8 | 0 (0.0%) |
| Embedded systems | 8 | 1 (12.5%) |
| Deployment experience | 7 | 3 (42.9%) |
| Web systems | 7 | 4 (57.1%) |
| Workload characterization | 6 | 0 (0.0%) |
| Energy and power management | 5 | 1 (20.0%) |
| Mobile and wireless computing | 5 | 2 (40.0%) |
| Middlebox systems | 3 | 0 (0.0%) |
| Content distribution networks | 2 | 1 (50.0%) |
| Multimedia systems | 2 | 2 (100.0%) |
Common threads
- Data centers
- High-performance data processing
- Verification and bug finding
- Security and containment
- Programmable infrastructure
Hyperkernel: Push-Button Verification of an OS Kernel
This paper describes an approach to designing, implementing, and formally verifying the functional correctness of an OS kernel, named Hyperkernel, with a high degree of proof automation and low proof burden. We base the design of Hyperkernel's interface on xv6, a Unix-like teaching operating system. Hyperkernel introduces three key ideas to achieve proof automation: it finitizes the kernel interface to avoid unbounded loops or recursion; it separates kernel and user address spaces to simplify reasoning about virtual memory; and it performs verification at the LLVM intermediate representation level to avoid modeling complicated C semantics.
We have verified the implementation of Hyperkernel with the Z3 SMT solver, checking a total of 50 system calls and other trap handlers. Experience shows that Hyperkernel can avoid bugs similar to those found in xv6, and that the verification of Hyperkernel can be achieved with a low proof burden.
Canopy: An End-to-End Performance Tracing And Analysis System
This paper presents Canopy, Facebook's end-to-end performance tracing infrastructure. Canopy records causally related performance data across the end-to-end execution path of requests, including from browsers, mobile applications, and backend services. Canopy processes traces in near real-time, derives user-specified features, and outputs to performance datasets that aggregate across billions of requests. Using Canopy, Facebook engineers can query and analyze performance data in real-time. Canopy addresses three challenges we have encountered in scaling performance analysis: supporting the range of execution and performance models used by different components of the Facebook stack; supporting interactive ad-hoc analysis of performance data; and enabling deep customization by users, from sampling traces to extracting and visualizing features. Canopy currently records and processes over 1 billion traces per day. We discuss how Canopy has evolved to apply to a wide range of scenarios, and present case studies of its use in solving various performance challenges.
My VM is Lighter (and Safer) than your Container
Containers are in great demand because they are lightweight when compared to virtual machines. On the downside, containers offer weaker isolation than VMs, to the point where people run containers in virtual machines to achieve proper isolation. In this paper, we examine whether there is indeed a strict tradeoff between isolation (VMs) and efficiency (containers). We find that VMs can be as nimble as containers, as long as they are small and the toolstack is fast enough.
We achieve lightweight VMs by using unikernels for specialized applications and with Tinyx, a tool that enables creating tailor-made, trimmed-down Linux virtual machines. By themselves, lightweight virtual machines are not enough to ensure good performance since the virtualization control plane (the toolstack) becomes the performance bottleneck. We present LightVM, a new virtualization solution based on Xen that is optimized to offer fast boot-times regardless of the number of active VMs. LightVM features a complete redesign of Xen's control plane, transforming its centralized operation to a distributed one where interactions with the hypervisor are reduced to a minimum. LightVM can boot a VM in 2.3ms, comparable to fork/exec on Linux (1ms), and two orders of magnitude faster than Docker. LightVM can pack thousands of LightVM guests on modest hardware with memory and CPU usage comparable to that of processes.
PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees
Key-value stores such as LevelDB and RocksDB offer excellent write throughput, but suffer high write amplification. The write amplification problem is due to the Log-Structured Merge Trees data structure that underlies these key-value stores. To remedy this problem, this paper presents a novel data structure that is inspired by Skip Lists, termed Fragmented Log-Structured Merge Trees (FLSM). FLSM introduces the notion of guards to organize logs, and avoids rewriting data in the same level. We build PebblesDB, a highperformance key-value store, by modifying HyperLevelDB to use the FLSM data structure. We evaluate PebblesDB using micro-benchmarks and show that for write-intensive workloads, PebblesDB reduces write amplification by 2.4-3× compared to RocksDB, while increasing write throughput by 6.7×. We modify two widely-used NoSQL stores, MongoDB and HyperDex, to use PebblesDB as their underlying storage engine. Evaluating these applications using the YCSB benchmark shows that throughput is increased by 18-105% when using PebblesDB (compared to their default storage engines) while write IO is decreased by 35-55%.
Datacenter RPCs can be General and Fast
It is commonly believed that datacenter networking software must sacrifice generality to attain high performance. The popularity of specialized distributed systems designed specifically for niche technologies such as RDMA, lossless networks, FPGAs, and programmable switches testifies to this belief. In this paper, we show that such specialization is not necessary. eRPC is a new general-purpose remote procedure call (RPC) library that offers performance comparable to specialized systems, while running on commodity CPUs in traditional datacenter networks based on either lossy Ethernet or lossless fabrics. eRPC performs well in three key metrics: message rate for small messages; bandwidth for large messages; and scalability to a large number of nodes and CPU cores. It handles packet loss, congestion, and background request execution. In microbenchmarks, one CPU core can handle up to 10 million small RPCs per second, or send large messages at 75 Gbps. We port a production-grade implementation of Raft state machine replication to eRPC without modifying the core Raft source code. We achieve 5.5 microseconds of replication latency on lossy Ethernet, which is faster than or comparable to specialized replication systems that use programmable switches, FPGAs, or RDMA.
The FuzzyLog: A Partially Ordered Shared Log
The FuzzyLog is a partially ordered shared log abstraction. Distributed applications can concurrently append to the partial order and play it back. FuzzyLog applications obtain the benefits of an underlying shared log – extracting strong consistency, durability, and failure atomicity in simple ways – without suffering from its drawbacks. By exposing a partial order, the FuzzyLog enables three key capabilities for applications: linear scaling for throughput and capacity (without sacrificing atomicity), weaker consistency guarantees, and tolerance to network partitions. We present Dapple, a distributed implementation of the FuzzyLog abstraction that stores the partial order compactly and supports efficient appends / playback via a new ordering protocol. We implement several data structures and applications over the FuzzyLog, including several map variants as well as a ZooKeeper implementation. Our evaluation shows that these applications are compact, fast, and flexible: they retain the simplicity (100s of lines of code) and strong semantics (durability and failure atomicity) of a shared log design while exploiting the partial order of the FuzzyLog for linear scalability, flexible consistency guarantees (e.g., causal+ consistency), and network partition tolerance. On a 6-node Dapple deployment, our FuzzyLog-based ZooKeeper supports 3M/sec single-key writes, and 150K/sec atomic cross-shard renames.
Taming Performance Variability
The performance of compute hardware varies: software run repeatedly on the same server (or a different server with supposedly identical parts) can produce performance results that differ with each execution. This variation has important effects on the reproducibility of systems research and ability to quantitatively compare the performance of different systems. It also has implications for commercial computing, where agreements are often made conditioned on meeting specific performance targets.
Over a period of 10 months, we conducted a large-scale study capturing nearly 900,000 data points from 835 servers. We examine this data from two perspectives: that of a service provider wishing to offer a consistent environment, and that of a systems researcher who must understand how variability impacts experimental results. From this examination, we draw a number of lessons about the types and magnitudes of performance variability and the effects on confidence in experiment results. We also create a statistical model that can be used to understand how representative an individual server is of the general population. The full dataset and our analysis tools are publicly available, and we have built a system to interactively explore the data and make recommendations for experiment parameters based on statistical analysis of historical data.
An Analysis of Network-Partitioning Failures in Cloud Systems
Link - Related: http://jepsen.io/
We present a comprehensive study of 136 system failures attributed to network-partitioning faults from 25 widely used distributed systems. We found that the majority of the failures led to catastrophic effects, such as data loss, reappearance of deleted data, broken locks, and system crashes. The majority of the failures can easily manifest once a network partition occurs: They require little to no client input, can be triggered by isolating a single node, and are deterministic. However, the number of test cases that one must consider is extremely large. Fortunately, we identify ordering, timing, and network fault characteristics that significantly simplify testing. Furthermore, we found that a significant number of the failures are due to design flaws in core system mechanisms. We found that the majority of the failures could have been avoided by design reviews, and could have been discovered by testing with network-partitioning fault injection. We built NEAT, a testing framework that simplifies the coordination of multiple clients and can inject different types of network-partitioning faults. We used NEAT to test seven popular systems and found and reported 32 failures.
Neural Adaptive Content-aware Internet Video Delivery
Internet video streaming has experienced tremendous growth over the last few decades. However, the quality of existing video delivery critically depends on the bandwidth resource. Consequently, user quality of experience (QoE) suffers inevitably when network conditions become unfavorable. We present a new video delivery framework that utilizes client computation and recent advances in deep neural networks (DNNs) to reduce the dependency for delivering high-quality video. The use of DNNs enables us to enhance the video quality independent to the available bandwidth. We design a practical system that addresses several challenges, such as client heterogeneity, interaction with bitrate adaptation, and DNN transfer, in enabling the idea. Our evaluation using 3G and broadband network traces shows the proposed system outperforms the current state of the art, enhancing the average QoE by 43.08% using the same bandwidth budget or saving 17.13% of bandwidth while providing the same user QoE.
Rethink the Sync
We introduce external synchrony, a new model for local file I/O that provides the reliability and simplicity of synchronous I/O, yet also closely approximates the performance of asynchronous I/O. An external observer cannot distinguish the output of a computer with an externally synchronous file system from the output of a computer with a synchronous file system. No application modification is required to use an externally synchronous file system. In fact, application developers can program to the simpler synchronous I/O abstraction and still receive excellent performance. We have implemented an externally synchronous file system for Linux, called xsyncfs. Xsyncfs provides the same durability and ordering-guarantees as those provided by a synchronously mounted ext3 file system. Yet even for I/O-intensive benchmarks, xsyncfs performance is within 7% of ext3 mounted asynchronously. Compared to ext3 mounted synchronously, xsyncfs is up to two orders of magnitude faster.
Kernel programming vs. systems research
- Systems programming concerns API constraints
- Naming them
- Working with them
- Breaking them
- Systems programming involves large code bases
- Kernel programming an excellent primer
- Understand the constraints: what, why
- Understand how and when to break them
What does systems research feel like?
What does systems research feel like?
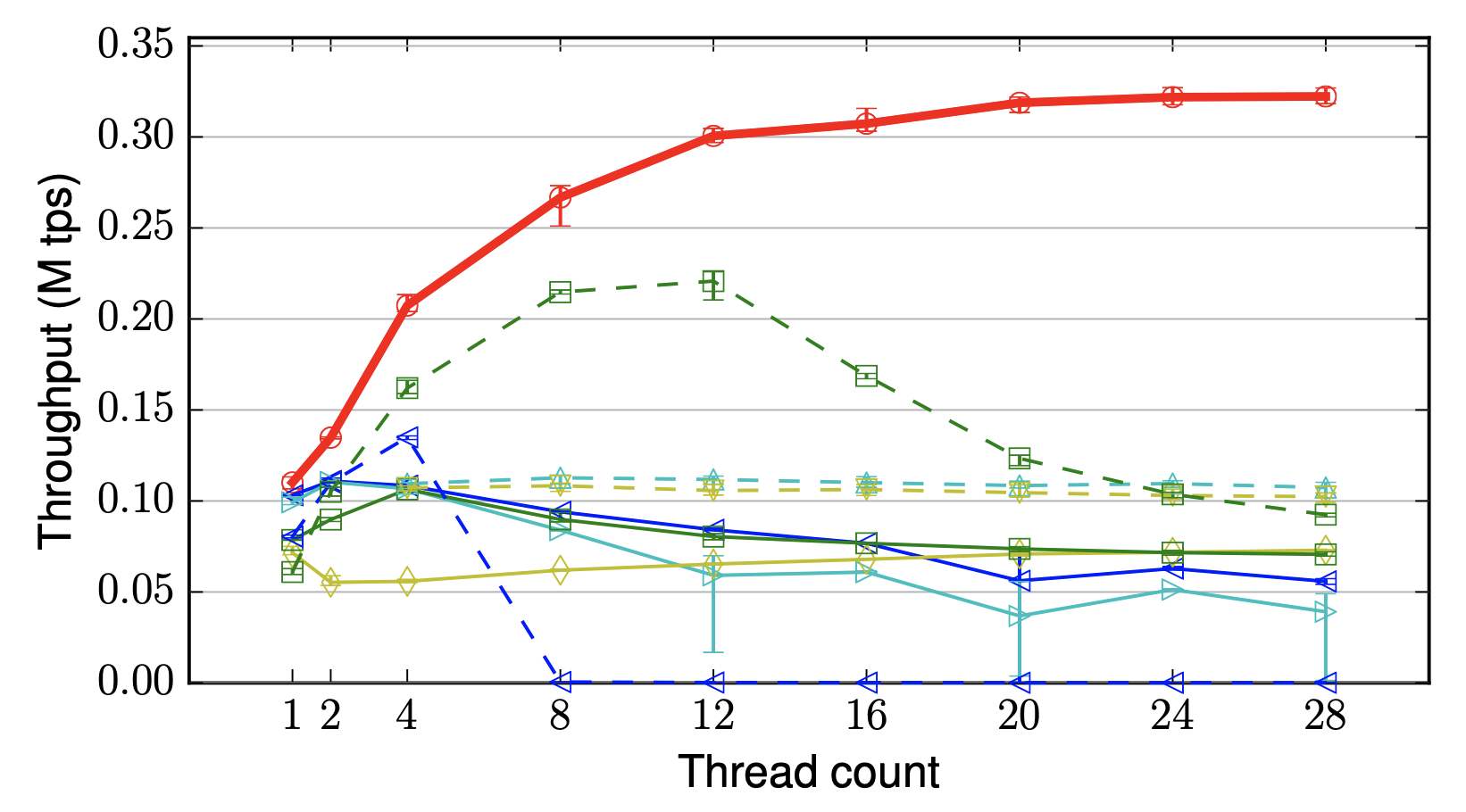
What does systems research feel like?
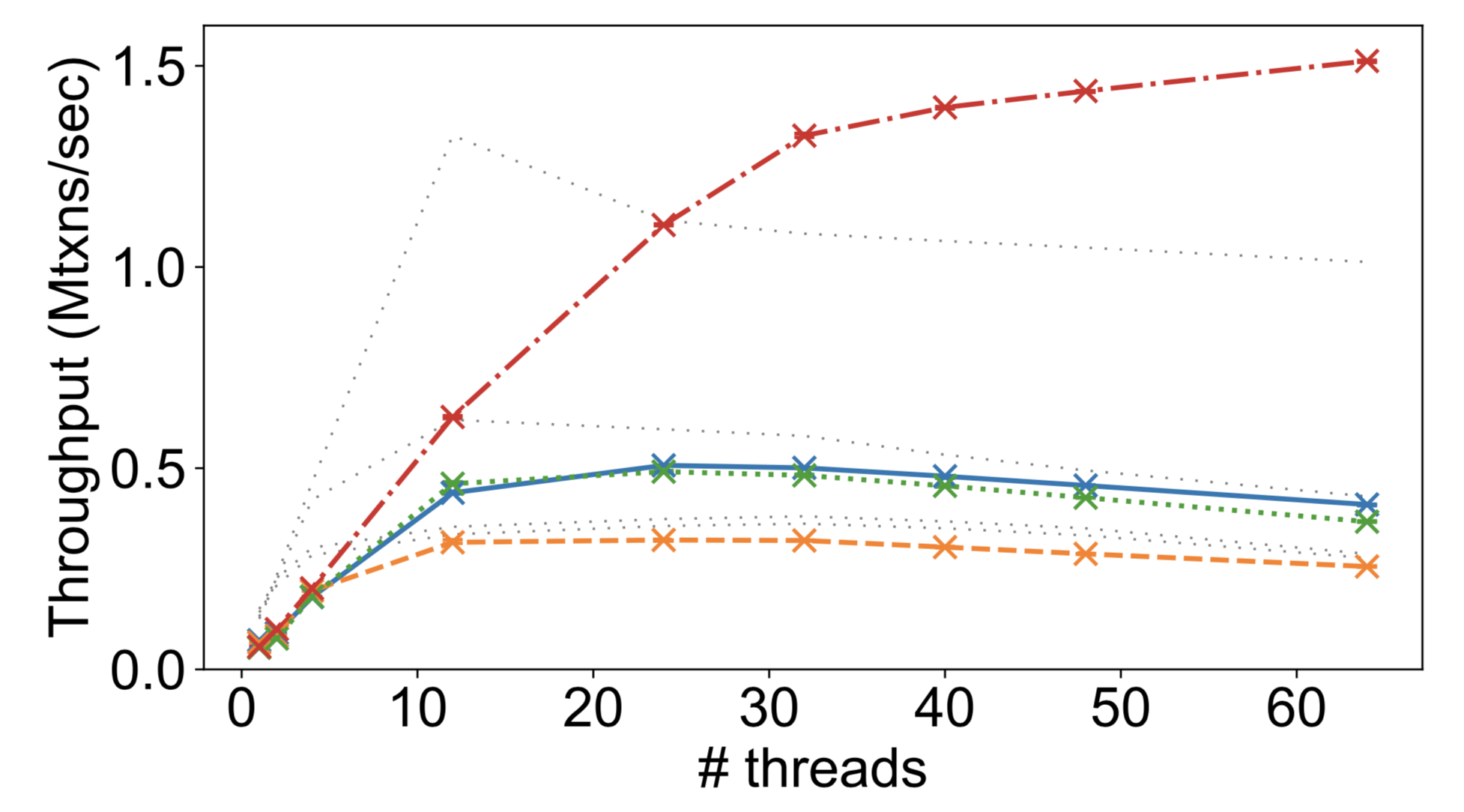
What does systems research feel like?
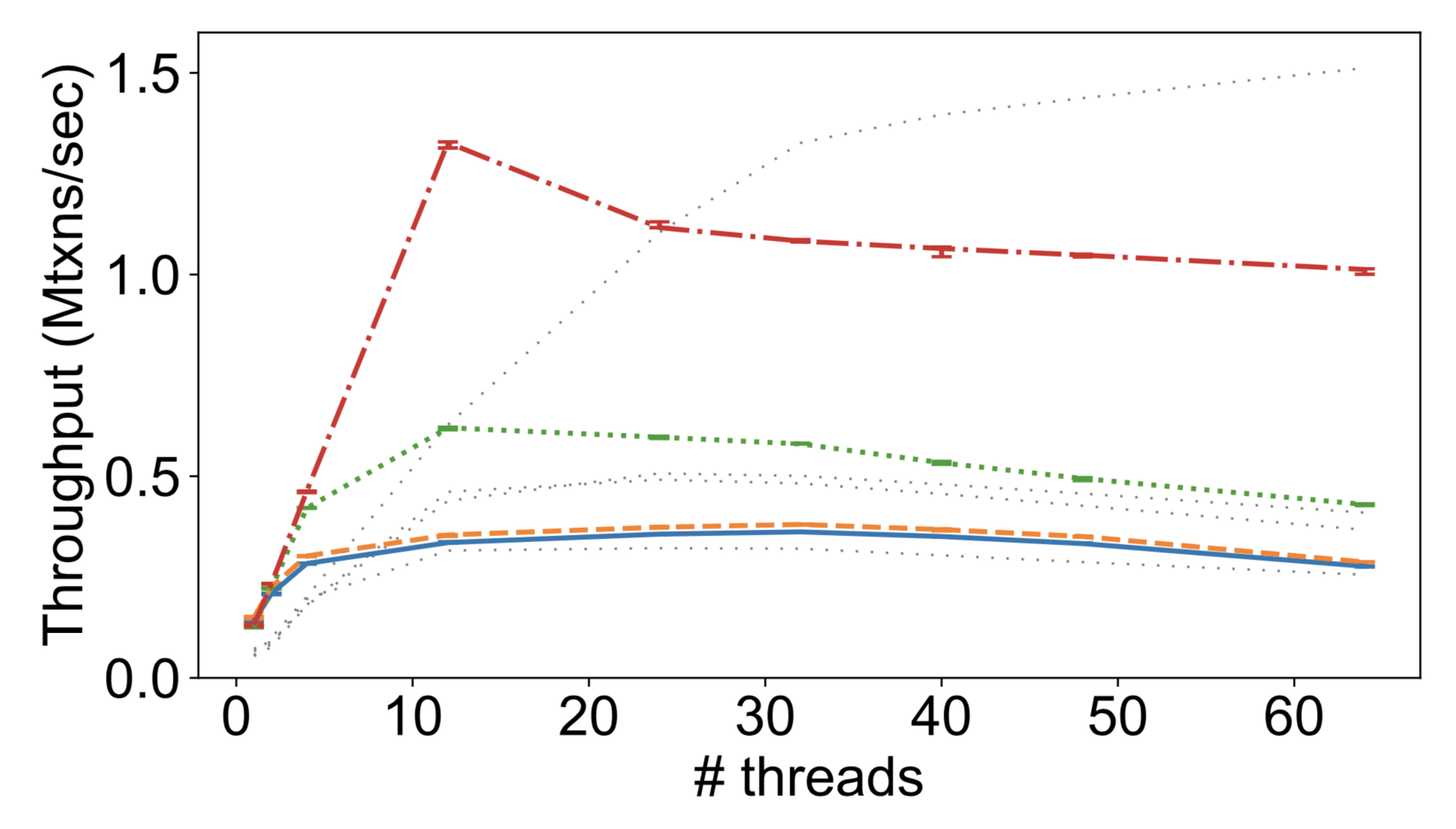
What does systems research feel like?
- Write some code
- Figure something out
- Maybe change the world
Where to go from here?
- CS 261 (on hiatus)
- CS 263 (fall)
- CS 260r (on hiatus)
- CS 145/245 (spring)
- CS 165 (fall)
- CS 265 (spring)
- CS 152 (spring)
- CS 153 (fall)
- CS 252r (spring)
- CS 141 (spring)
- CS 247r (fall)
- Independent study
- Thesis!