These initial exercises get you acclimated to the Chickadee OS code and our documentation. They are focused on virtual memory.
Turnin
Fill out psets/pset1answers.md and psets/pset1collab.md and push to
GitHub. Then configure our grading server to recognize your code.
Intermediate checkin: Turn in Parts A and B by 11:59pm Monday 2/3.
Final checkin: Turn in all parts by 11:59pm Wednesday 2/12.
Run it
Create your personal fork of the Chickadee repository using our GitHub
Classroom link. Then clone that Chickadee to your development environment
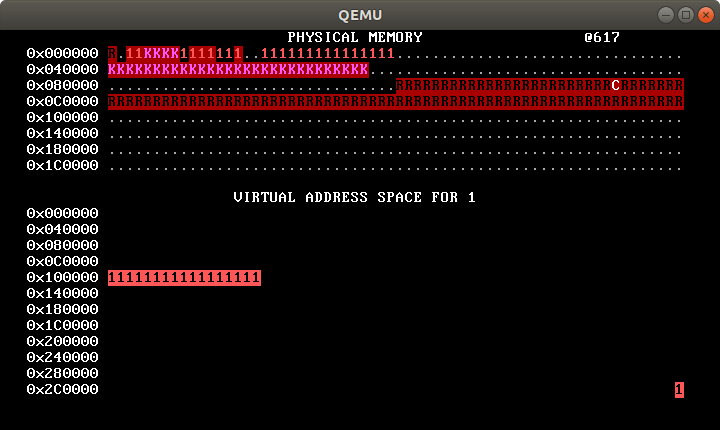
(instructions for Linux and Mac OS X below). When you’re ready, make run
should pop up a window like this, with red “1”s gradually marching to the
right:
Linux instructions
The native Chickadee build environment is Linux. To use Linux, either set up your own Linux machine or prepare and install a Linux virtual machine on your preferred computer. The instructions on the CS 61 Infrastructure page are a good guideline. We have generally recommended VMware Fusion for Mac machines, and students can install VMware Fusion for free through an academic program (contact us). There are other virtual machines, such as VirtualBox and Parallels, that some students prefer.
You need a recent version of your preferred Linux distribution because you
want a recent compiler—GCC 7 or GCC 8 if possible. Eddie uses Ubuntu
18.04, on which GCC 7 is the default.
You can also install GCC 7 on many distributions as a non-default package; our
Makefiles attempt to use gcc-7 if gcc appears old. You can use
Clang, but only version 5 or later will work.
Mac OS X instructions
You will need a crosscompiler and an installation of QEMU. The following steps have worked for Eddie:
- Install Homebrew.
- Install Homebrew’s new GCC package:
brew install gcc@8 - Install Homebrew’s QEMU:
brew install qemu - Tap Sergio Benitez’s collection of cross-compilers:
brew tap SergioBenitez/osxct - Install the
x86_64-unknown-linux-gnucross-compiler toolchain:brew install x86_64-unknown-linux-gnu Edit the file
config.mkin your Chickadee directory to contain this:CCPREFIX=x86_64-unknown-linux-gnu- HOSTCC=gcc-8 HOSTCXX=g++-8(Do not add
config.mkto your repository, since it is intended for local configuration.)
Chickadee overview
Chickadee is based on WeensyOS, so a lot of it may feel familiar to you. But there are important differences. Chickadee, unlike WeensyOS, is a multiprocessor operating system; and Chickadee, unlike WeensyOS, supports kernel task suspension: a Chickadee kernel processing a system call on behalf of one process can suspend itself, either voluntarily or because of an interrupt, and allow other tasks to run, resuming later in kernel space exactly where it left off. Kernel task suspension has profound effects on operating system structure.
A. Memory allocator
The Chickadee kernel memory allocator is located in k-alloc.cc. It supports
allocating physical memory one page at a time. It doesn’t support larger or
smaller allocations, or freeing memory—you’ll address those issues later.
Answer the following questions about k-alloc.cc. You may find the
documentation useful. Write up your answers in a text or Markdown
file, such as psets/pset1answers.md; you will turn this file in.
What is the maximum
sizesupported bykalloc()?What is the first address returned by
kalloc()? Uselog_printfto determine the answer experimentally, then explain this answer from the code. (See Memory iterators for more information on thephysical_rangesobject.)What is the largest address returned by
kalloc()? (You may want to reduceALLOC_SLOWDOWNand disable thesys_pausecall inp-allocator.ccso the allocation process runs faster, but don’t forget to undo these changes.)Does
kalloc()return physical addresses, high canonical (kernel virtual) addresses, or kernel text addresses? (See Memory layout.) What line of code determines this?What one-line change to some
.ccfile other thank-alloc.ccwould allowkalloc()to use 0x300000 bytes of physical memory? Test your answer.Rewrite the “skip over reserved and kernel memory” loop so that it is simpler. You will use
physical_ranges.type()(and, perhaps,physical_ranges.limit()) rather thanphysical_ranges.find(). Paste your loop into your answers file.The loop using
type()is simpler than the loop usingfind(), but the loop usingfind()has other advantages. What are they? Give a quantitative answer.What bad thing could happen if there was no
page_lock?
B. Memory viewer
The Chickadee kernel displays physical and virtual memory maps on the console.
These memory maps are calculated differently than in WeensyOS, where an
explicit pageinfo array tracked how each physical page was allocated. You’ll
introduce a pageinfo-like structure in problem set 2. The current memory
viewer instead computes a memory map every time it runs, using
physical_ranges and process page tables.
Answer the following questions about memusage::refresh() in
k-memviewer.cc.
Which line of code marks physical page 0x100000 as kernel-restricted?
Which line of code marks
struct procmemory as kernel-restricted?The
ptiterloop marks pages as kernel-restricted, whereas thevmiterloop marks pages as user-accessible. Why this distinction? What kinds of pages are involved in each case? What bad things could occur if the pages marked by theptiterloop were user-accessible?All pages marked by the
pidloop should have the samemem_type constant (i.e.,physical_ranges.type()will return the same value for each page). What is that memory type? Why is this true?In the
vmiterloop, replaceit.next()withit += PAGESIZE. What happens? Give a qualitative answer (what does QEMU do?) and a brief explanation.memusage::refresh()aims to capture all allocated memory, but it fails to do so: on the top line of the physical memory map you should see three periods., indicating three allocated pages thatmemusagemissed. (If youmake run NCPU=XforX≠2, you’ll see more or fewer periods. Hm!) Where are those pages allocated, and (if you can tell) what are their purposes?Hint: Add debugging code to
kalloc()to figure this out. Thelog_backtracefunction may be useful, coupled withobj/kernel.symand/orobj/kernel.asm.Change
memusage::refresh()so it captures all allocated pages.
C. Entry points
A C++ entry point is a code location that explicitly transfers control to a C++ function, on a new stack, via assembly. That is, it is a code location where a C++ function begins executing on a stack, where any prior uses of that stack were pure assembly functions.
Each process has just one entry point, namely process_main. Here’s how
that’s set up:
- The
process.ldlinker script marksprocess_mainas the program’s entry point. This entry point is recorded in the ELF executable file. - The
proc_loaderloader functions extract this entry point. - The
boot_process_startfunction inkernel.cccopies the entry point into the newly-initialized process’sripregister, so that the nextproc::resumecall (which uses assembly) transfers control there via theiretinstruction.
Of course, C++ code in processes can resume at many other locations, such as after a system call instruction or after an interrupt. But those resumption locations use a stack that was already set up, where C++ code was already running, not a new stack.
Question: The boot loader and kernel have seven more C++ entry points.
List them in pset1answers.md and briefly describe the circumstances under
which they are called.
Hint: You can find five of the entry points by looking at the assembly
code in k-exception.S; look for call and jmp instructions. The sixth
kernel entry point may be a little harder to find. 🙃 Look for a while, then
ask around.
Going further (optional): The System V Application Binary Interface for x86-64 machines governs the C/C++ calling convention for x86-64 programs. Part of it states that at function entry, the stack address should equal
16*N + 8for some integerN. This means that when a compiled C++ function begins executing, the stack pointer should be 8 bytes off 16-byte alignment. Much code will work correctly on any alignment, but certain special instructions will fail if the alignment is off.Compilers and operating systems cooperate to enforce this alignment convention. The operating system should set up every C++ entry point to have the correct alignment. Thereafter, the compiler will preserve the correct alignment by making every stack frame a multiple of 16 bytes.
For optional extra work, assert at each C++ entry point that the stack is correctly aligned, and fix any alignment errors you find.
Hint: The Chickadee kernel and applications are compiled with
-fno-omit-frame-pointer. This option tells GCC to maintain a base or frame pointer register that can be used to trace through stack frames. On x86-64, the%rbpregister is the frame pointer. You’ll notice that all C++-compiled functions start and end with similar assembly code:prologue: pushq %rbp movq %rsp, %rbp ... function body ... epilogue: popq %rbp retq(You might also see the epilogue
leaveq; retq, which is equivalent tomovq %rbp, %rsp; popq %rbp; retq.) As a result, every C++ function will have a similar stack layout:~ ~ ^ higher addresses | caller | | data | +-------------------+ | return address | +-------------------+ <- %rsp at function entry | saved %rbp | +-------------------+ <- current %rbp == (%rsp at entry) - 8 | this function’s | | locals, callee- | | saved regs, etc. | ~ (may be empty) ~ +-------------------+ <- current %rsp | “red zone” | | (locals allowed | | for 128 bytes) | ~ ~In consequence:
- All of this function’s stack storage is located in addresses less than
%rbp.%rbpshould always be 16-byte aligned. (It is 8 bytes less than a value that is 8 bytes off of 16-byte aligned.)- The value in
(%rbp)(in C++ terms,*reinterpret_cast<uintptr_t*>(rdrbp())) is the caller’s%rbp. This lets us trace backwards through callers’ stack frames, as inlog_backtrace.- The value in
8(%rbp)(in C++ terms,*reinterpret_cast<uintptr_t*>(rdrbp() + 8)) is the return address.
D. Console
Chickadee processes don’t have access to console memory. Introduce a new
system call, sys_map_console(void* addr), that maps the console at a
user-specified address. You will need:
A
SYSCALL_MAP_CONSOLEconstant (for both processes and kernel).A
sys_map_console(void* addr)function (for processes).A kernel implementation for
SYSCALL_MAP_CONSOLE. As always in the kernel, be prepared for user error: your system call return E_INVAL if theaddrargument is not page-aligned or is not in low canonical memory (i.e., is greater thanVA_LOWMAX). The physical address of the console isCONSOLE_ADDR, defined inx86-64.h.
Then change p-allocator.cc to map console memory and then modify the
console. We like purple stars, so did this; you do something else:
sys_map_console(console);
for (int i = 0; i < CONSOLE_ROWS * CONSOLE_COLUMNS; ++i) {
console[i] = '*' | 0x5000;
}
If you’re confused about where to put stuff, try git grep. For
instance, try git grep SYSCALL or git grep sys_.
E. Fork
The current kernel’s SYSCALL_FORK implementation always returns E_NOSYS. Now
you will make a real fork implementation.
To fork a process, the kernel must start a new context. That involves:
- You reading about contexts.
- The kernel allocating a new PID.
- Allocating a
struct procand a page table. - Copying the parent process’s user-accessible memory and mapping the copies into the new process’s page table.
- Initializing the new process’s registers to a copy of the old process’s registers.
- Storing the new process in the process table.
- Arranging for the new PID to be returned to the parent process and 0 to be returned to the child process.
- Enqueueing the new process on some CPU’s run queue.
If any of these steps fail except the first (because the system is out of PIDs
or memory), fork should return an error to the parent. Chickadee doesn’t
know how to free memory yet, so don’t worry about memory leaks.
Things to note:
- For inspiration, check out the other function that creates a new process,
boot_process_start. - This is a multicore kernel, so shared structures are protected by locks and invariants, including these:
- The
ptable(process table) is protected byptable_lock. You should not examine or modifyptableunlessptable_lockis locked. - A CPU’s run queue is protected by its
runq_lock_member. Thecpu->enqueue(proc*)function acquires and releases that lock. - It is only safe to access a process’s
regs_member before the process is scheduled.
- The
- Use
kalloc_pagetable()to allocate an initial page table. This function initializes the new page table with the required kernel mappings. vmiteris your friend.- The child process will “return” to user mode using a different code path than the parent process. (Which code path will it use?)
- If the kernel makes a bad enough mistake, QEMU will enter a reboot loop. Try
make run D=1if this happens.D=1tells QEMU to print out debug information about machine faults and exceptions, such as the address that caused a kernel fault. It also tells QEMU to quit on error instead of rebooting. - Optional: Forking a process can take a long time, so it would be kind to
enable interrupts by calling
sti()before starting the expensive task of copying memory. This will ensure important interrupts are not delayed for too long. But make sure you have fork working before you addsti().
Once you have implemented fork correctly, your make run-allocator memory map
should feature four processes with different allocation speeds, just as in
WeensyOS.
F. Stack canaries
Chickadee collocates kernel stack data, such as local variables and stored
registers, with other data. Each page holding a struct proc contains a
kernel task stack at its upper end, and each page holding a struct cpustate
contains a kernel CPU stack at its upper end. (See Contexts.) This means
that if a stack grows too much—because of too-deep recursion, or large local
variables—the stack will collide with important data and corrupt the kernel.
Demonstrate this problem by adding a system call that corrupts a kernel structure if it is called. (The corruption doesn’t need to be silent; for instance, the kernel might fail an assertion or eventually reboot.) Modify
p-nastyalloc.ccto call this system call (make run-nastyallocwill run it).Add canaries to the relevant kernel structures to detect this problem and turn it into an assertion failure. A canary is a piece of data with a known value, placed in a location vulnerable to inadvertent corruption. To check the canary, you compare its current value with the expected value; any difference indicates disaster. Add code to set the canaries in relevant kernel structures and code to check them. For instance, you might check canaries before system calls return, or you might introduce a kernel task that periodically checks all system canaries.
Your canary code should detect the problem induced by
p-nastyalloc. It need not detect every possible problem, though (that would be impossible).You can use GCC options to detect some too-large stacks statically. Check out
-Wstack-usage. Does-Wstack-usagedetect the problem you added in step 1? (Optional advanced work: Could-fstack-usagedetect it?)
G. Kernel buddy allocator
The existing Chickadee allocator can only allocate memory in units of single pages, and it cannot free memory. That’s bad!
Freeing memory is not too hard to support; a singly-linked free list of pages
could work. But we seek an efficient allocator for variable-sized
allocations. For instance, Chickadee kernel stacks are currently limited to a
couple thousand bytes because struct procs are allocated in units of single
pages: a buddy allocator would let us support deeper stacks. And some later
hardware structures, such as the structure for disk communication, require
larger amounts of contiguous memory.
In this part, you will therefore implement a
buddy allocator
for kernel memory. Complete the following functions in
k-alloc.cc:
void* kalloc(size_t sz)void kfree(void* ptr)void init_kalloc()
kalloc and kfree are the malloc and free equivalents. init_kalloc()
should perform any initialization necessary so that the allocator has access
to all available physical memory (i.e., physical memory with type
mem_available in physical_ranges).
Also add testing infrastructure for your buddy allocator. Running make
run-testkalloc should execute some allocator tests in the kernel. This will
likely require adding a new system call as well as the tests themselves.
Testing is super important! Do not wait to implement tests—you should develop the tests in parallel with the allocator. See below for testing hints.
Buddy allocation
The buddy allocation algorithm is one of the oldest general algorithms for memory allocation. (It was invented in 1963!) Buddy allocation supports efficient splitting (breaking large contiguous blocks of free memory into smaller pieces) and coalescing (merging adjacent free blocks into larger contiguous blocks).
Buddy allocation is based on powers of 2 called orders. An allocation request of size \(s\) uses a block of size \(2^o\) and order \(o\), where
\[o = \left\lceil \log_2 s \right\rceil.\]
For example, an allocation request of size 4095 will use a block of size 4096 and order 12, but an allocation request of size 4097 will use a block of size 8192 and order 13. The physical address of a block of order \(o\) is always a multiple of \(2^o\).
Allocation splits large blocks until there’s a free block with the right size.
- Let
obe the desired order for the allocation. - Find a free block with order
o. If found, return that block. - Otherwise, find a free block with order
x > o, minimizingx. If found:- Split the block in two, creating two free blocks with order
x-1. These two blocks are called order-(x-1)buddies because they are adjacent blocks with orderx-1, and the address of one is easily calculated from the address of the other. - Repeat step 2.
- Split the block in two, creating two free blocks with order
- If there’s no larger free block, the allocation fails: return
nullptr.
Freeing coalesces freed buddies whenever possible. This can create large contiguous free blocks very efficiently.
- Let
obe the order of the freed block. - Check whether the freed block’s order-
obuddy is also completely free. If it is:- Coalesce the freed block and the buddy into a single free block of order
o + 1. - Repeat step 2.
- Coalesce the freed block and the buddy into a single free block of order
Buddy allocators have low external fragmentation (unusable space between allocated blocks) because they aggressively coalesce freed memory into larger blocks. Their internal fragmentation (unused space inside allocated blocks) is at most 50%. Many real-world allocators use buddy allocation, often coupled with other techniques (for, e.g., efficient multicore support); for instance, both Linux and jemalloc use buddy allocation.
Designing your allocator
Your buddy allocator will use two constant parameters, min_order and
max_order, which are the minimum and maximum orders the allocator supports.
Your allocator will have min_order 12, so every allocation request will use
at least a page of memory. (Note that this increases the maximum internal
fragmentation.) It should have max_order at least 21, allowing it to support
contiguous allocations of up to 2MiB.
Your allocator will maintain at least the following state.
- An array that tracks the state of every physical page in the system.
Specifically, for physical page number
p(i.e., the page with physical addressp * PAGESIZE) that is the beginning of an allocated or free block,pages[p]should say:- Whether the page is free or not.
- The order of the block.
- One free list per order.
- The list heads will be global.
- You will also need a way to link free blocks together.
The pages array lets you quickly check whether a buddy is free. The free
lists lets you quickly find a free block of a given order. Both these
operations are O(1), and there are a constant number of orders, so both
kalloc and kfree should take O(1) time.
You own the definition of the page structure and the pages array (and you
can call the array something else if you want). You will add more information
to the array later.
Allocation and sanitizers
Integrate your buddy allocator with Chickadee’s sanitizer support. This will help the sanitizers warn on bugs like double-free and wild-write errors.
Upon allocating
Bbytes of memory at physical addresspa, yourkallocfunction should callasan_mark_memory(pa, B, false). This tells the sanitizer thatBbytes starting at physical addresspaare valid to access.Upon freeing a block with order
oat physical addresspa, yourkfreefunction should callasan_mark_memory(pa, 1 << o, true). This tells the sanitizer to poison the freed block: accesses to its memory will cause warnings.
The asan_mark_memory function calls will do nothing unless sanitization is
enabled.
Testing
Buddy allocation has tricky corner cases, and a testing strategy will be
important for success. We expect you to write tests for your buddy allocator
as assertions in kalloc and kfree, and/or in the test_kalloc function.
Test failures should appear as assertion failures that panic the kernel.
A successful testing strategy has two parts: make bugs detectable, and make them frequent. Your code should make bugs easy to detect (it works best if you design your code with testing in mind), and your tests should be so comprehensive that even rare bugs are likely to occur during testing.
The classic way to make bugs detectable involves invariants and
assertions. An invariant is a property that should always hold of correct
code; an assertion is an executable statement that checks an invariant.
Buddy allocators have many useful invariants; for instance, if an order-o
block is free, then either o == max_order or the block’s order-o buddy is
wholly or partially allocated. Assertions of this invariant in the kalloc
code can potentially detect many bugs. Those assertions can work locally, a
bit at a time, or globally, considering all available data. For instance, a
local assertion about free blocks might run once, in kfree, to check that
the freed block meets the invarant after block coalescing; a global assertion
about free blocks might check every free block in the system by searching free
lists. Local invariants are typically more efficient to check, and the best
ones are so efficient that there’s no harm leaving them on in production
builds. Global invariants may be many times more expensive, but they typically
catch more bugs.
A good way to make bugs frequent is to use random testing, such as a long sequence of random allocations and frees. Random testing requires art, however: the tester must not do anything illegal (such as a double-free), and naive random testing can “get stuck” in conceptually-uninteresting states without exploring corner cases.
You may be interested in several testing- and assertion-related blog posts by John Regehr of the University of Utah:
Hints
There are some useful math functions in lib.hh. You might especially like
msb(x), which returns the index of the most significant 1 bit in
x plus one. (For example, msb(1) == 1; msb(4095) == 12; msb(4096)
== 13. As a special case, msb(0) == 0.) There are also round_up_pow2 and
round_down_pow2.
There’s a generic doubly linked list type in k-list.hh.
This would be useful for building free lists; or you can build your own.
Make sure you add assertions to your code. You’ll probably also want some
helper functions, such as a function that returns a block’s order-o buddy,
and a function that confirms that a physical address is valid as an order-o
block.
Slab allocation (advanced optional work)
This style of buddy allocator is great for large objects, but because it
relies on a pages array with information about each min_order block, it
doesn’t scale to small allocation sizes (e.g., 64-byte allocations). For
smaller allocations, most systems switch to another allocation strategy, such
as slab allocation. Design and implement such an allocator.