![[Kernel, courtesy IowaFarmer.com CornCam]](kernel.jpg)
CS 235 Advanced Operating Systems, Winter 2008
Lab 1: Booting a PC
Due 11:59pm Friday, January 18
Introduction
This lab is split into three parts. The first part concentrates on getting familiarized with x86 assembly language, the QEMU x86 emulator, and the PC's power-on bootstrap procedure. The second part examines the boot loader for our class kernel, which resides in the boot directory of the lab1 tree. Finally, the third part delves into the initial template for our class kernel itself, named JOS, which resides in the kern directory.
Software Setup
First, prepare the compilers and simulators you'll use for the rest of the term. The tools page has directions for using the versions we've installed, and for downloading, configuring, and installing your own personal copies.
The files you'll start with for this lab are available in lab1.tar.gz. Download this file.
We expect you to use CVS, or a source code management system of your choice, to work with our code. If you haven't used CVS before this will be a great experience for you! Go to the CVS Hints page and follow the instructions there.
Hand-In Procedure
When you are ready to hand in your lab, run gmake tarball in the jos directory. This will create a file called lab1-yourusername.tar.gz, which you should submit via CourseWeb by 11:59pm on Friday, January 18. If you have problems with CourseWeb, you may also email me this file.
You do not need to turn in answers to any of the questions in the text of the lab. (Do answer them for yourself though! They will help with the rest of the lab.)
Additionally, you will need to choose a marked challenge problem (or design one of your own, after getting my approval). Write up a short description of your chosen challenge problem and how you solved it. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. Place the write-up in a file called answers.txt (plain text) or answers.html (HTML format) in the top level of your jos directory before handing in your work.
We will be grading your solutions with a grading program. You can run gmake grade to test your solutions with the grading program.
Part 1: PC Bootstrap
The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
Getting Started with x86 assembly
If you are not already familiar with x86 assembly language, you will quickly become familiar with it during this course! The PC Assembly Language Book is an excellent place to start. Hopefully, the book contains mixture of new and old material for you.
Warning: Unfortunately the examples in the book are written for the NASM assembler, whereas we will be using the GNU assembler. NASM uses the so-called Intel syntax while GNU uses the AT&T syntax. While semantically equivalent, an assembly file will differ quite a lot, at least superficially, depending on which syntax is used. Luckily the conversion between the two is pretty simple, and is covered in Brennan's Guide to Inline Assembly.
|
Exercise 1. Read or at least carefully scan the entire PC Assembly Language book, except that you
should skip all sections after 1.3.5 in chapter 1, which talk about
features of the NASM assembler that do not apply directly to the GNU
assembler. You may also skip chapters 5 and 6, and all sections under
7.2, which deal with processor and language features we won't use in
class.
Also read the section "The Syntax" in Brennan's Guide to familiarize yourself with the most important features of GNU assembler syntax. |
Certainly the definitive reference for x86 assembly language programming is Intel's instruction set architecture reference, which you can find on the class reference page in two flavors: an HTML edition of the old 80386 Programmer's Reference Manual, which is much shorter and easier to navigate than more recent manuals but describes all of the x86 processor features that we will make use of in class; and the full, latest and greatest IA-32 Intel Architecture Software Developer's Manuals from Intel, covering all the features of the most recent processors that we won't need in class but you may be interested in learning about. An equivalent (but even longer) set of manuals is available from AMD, which also covers the new 64-bit extensions now appearing in both AMD and Intel processors.
You should read the recommended chapters of the PC Assembly book, and "The Syntax" section in Brennan's Guide now. Save the Intel/AMD architecture manuals for later or use them for reference when you want to look up the definitive explanation of a particular processor feature or instruction.
Simulating the x86
Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon-version of an x86.In class we will use the QEMU Emulator, a modern and relatively fast emulator. Unfortunately, QEMU's debugging facilities are not very mature. QEMU's monitor lets you examine memory, but not modify memory, and you cannot set breakpoints in the machine. Nevertheless, we have found that most students rely on print messages to debug for most of the course, so we're moving to QEMU as an experiment.
We used the Bochs PC Emulator in previous quarters. It is slow and quirky, but has good debugging facilities. If you have serious problems that you think debugging might help, try downloading Bochs.
To get started, extract the Lab 1 files into your own directory on a class
machine as described above in "Software Setup". Once you have set up your
CVS repository and checked out the jos directory, type
gmake in the jos directory to build
the minimal class boot loader and kernel you will start with. (It's a
little generous to call the code we're running here a "kernel," but we'll
flesh it out throughout the quarter.)
% cd jos % gmake + mk mkbootdisk + as kern/entry.S + c++ kern/init.c + c++ kern/console.c + c++ kern/monitor.c + c++ kern/printf.c + c++ kern/kdebug.c + c++ lib/printfmt.c + c++ lib/readline.c + c++ lib/string.c + ld obj/kernel + as boot/boot.S + c++ -Os boot/main.c + ld boot/boot + mk obj/kernel.img %
Now you're ready to run QEMU, supplying the file obj/kernel.img, created above, as the contents of the emulated PC's "virtual hard disk." This hard disk image contains both our boot loader (obj/boot/boot) and our kernel (obj/kernel).
% gmake run
This executes qemu with the options required to set the
hard disk. (On Linux, the command is simply qemu -hda
obj/kernel.img.) You should see a window like this:
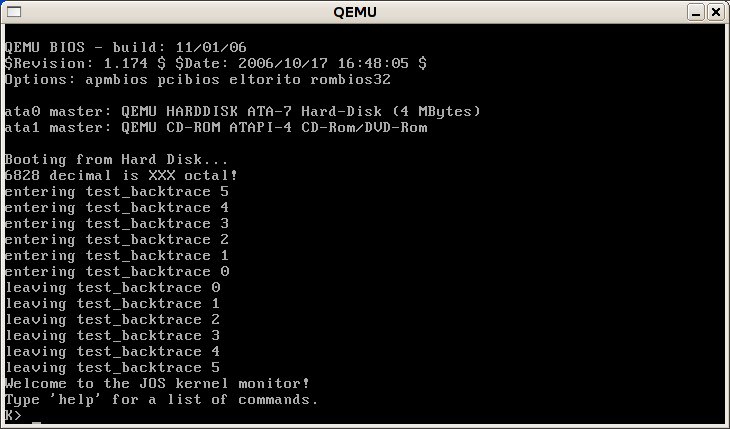
Press Ctrl-PageUp and
Ctrl-PageDown to scroll through previously
printed lines. (What code in kern/console.c makes this work?)
My mouse has disappeared! QEMU sometimes "grabs" the
mouse pointer, making it impossible for you to change to a different
window. If your computer stops responding, check the QEMU title bar. If
it says "Press Ctrl-Alt to exit grab", press Ctrl-Alt; you
should be able to move the mouse again.
Everything after 'Booting from Hard Disk...' was printed by our skeletal JOS kernel; the K> is the prompt printed by the small monitor, or interactive control program, that we've included in the kernel. The kernel monitor is currently pretty boring; it only knows about two commands:
K> help help - display this list of commands kerninfo - display information about the kernel K> kerninfo Special kernel symbols: _start f010000c (virt) 0010000c (phys) etext f0101843 (virt) 00101843 (phys) edata f0111548 (virt) 00111548 (phys) end f0111bc0 (virt) 00111bc0 (phys) Kernel executable memory footprint: 71KB K>
The help command is obvious, and we will shortly discuss the meaning of what the kerninfo command prints.
This kernel monitor is running "directly" on the "raw (virtual) hardware" of the simulated PC. This means that you should be able to copy the contents of obj/kernel.img onto the first few sectors of a real hard disk, insert that hard disk into a real PC, turn it on, and see exactly the same thing on the PC's real screen as you did above in the QEMU window. (We don't recommend you do this on a real machine with useful information on its hard disk, though, because copying kernel.img onto the beginning of its hard disk will trash the master boot record and the beginning of the first partition, effectively causing everything previously on the hard disk to be lost!)
To quit QEMU, press Ctrl-C in the terminal
window where you typed gmake run.
Bootstrapping and the PC's Physical Address Space
In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
Open two terminal windows. In one, enter gmake
run-gdb. This starts up QEMU, but QEMU stops just before the
processor executes the first instruction. The QEMU title bar says
"[Stopped]".
Now move to the QEMU window and type
Ctrl-Alt-2. This shifts control to
QEMU's monitor.
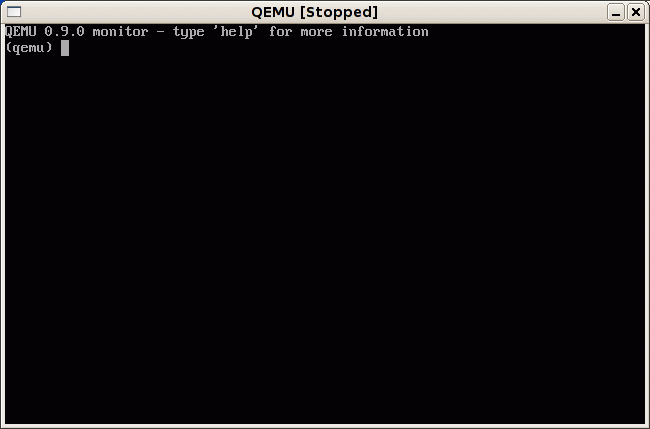
(You can shift back to the emulated computer's display by typing
Ctrl-Alt-1 although, since the computer hasn't
booted yet, the screen won't change.) Read a little about the commands you
can execute in QEMU's
documentation. For now, though, type info
registers. This gives you the state of the emulated PC's registers
just before the first instruction executes. This first
instruction is located in the emulated computer's BIOS, or Basic
Input/Output System -- the firmware that sets up the computer's state.
A PC's physical address space is hard-wired to have the following general layout:
+------------------+ <- 0xFFFFFFFF (4GB) | 32-bit | | BIOS and | | memory mapped | | devices | | | /\/\/\/\/\/\/\/\/\/\ /\/\/\/\/\/\/\/\/\/\ | | | Unused | | | +------------------+ <- depends on amount of RAM | | | | | Extended Memory | | | | | +------------------+ <- 0x00100000 (1MB) | BIOS ROM | +------------------+ <- 0x000F0000 (960KB) | 16-bit devices, | | expansion ROMs | +------------------+ <- 0x000C0000 (768KB) | VGA Display | +------------------+ <- 0x000A0000 (640KB) | | | Low Memory | | | +------------------+ <- 0x00000000 |
The first PCs, which were based on the 16-bit Intel 8088 processor, were only capable of addressing 1MB of physical memory. The physical address space of an early PC would therefore start at 0x00000000 but end at 0x000FFFFF instead of 0xFFFFFFFF. The 640KB area marked "Low Memory" was the only random-access memory (RAM) that an early PC could use; in fact the very earliest PCs only could be configured with 16KB, 32KB, or 64KB of RAM!
The 384KB area from 0x000A0000 through 0x000FFFFF was reserved by the hardware for special uses such as video display buffers and firmware held in nonvolatile memory. The most important part of this reserved area is the BIOS, which occupies the 64KB region from 0x000F0000 through 0x000FFFFF. More BIOS is located at the high end of the 32-bit address range as well. In early PCs the BIOS was held in true read-only memory (ROM), but current PCs store the BIOS in updateable flash memory. The BIOS is responsible for performing basic system initialization such as activating the video card and checking the amount of memory installed. After performing this initialization, the BIOS loads the operating system from some appropriate location such as floppy disk, hard disk, CD-ROM, or the network, and passes control of the machine to the operating system.
When Intel finally "broke the one megabyte barrier" with the 80286 and 80386 processors, which supported 16MB and 4GB physical address spaces respectively, the PC architects nevertheless preserved the original layout for the low 1MB of physical address space in order to ensure backward compatibility with existing software. Modern PCs therefore have a "hole" in physical memory from 0x000A0000 to 0x00100000, dividing RAM into "low" or "conventional memory" (the first 640KB) and "extended memory" (everything else). In addition, some space at the the very top of the PC's 32-bit physical address space, above all physical RAM, is now commonly reserved by the BIOS for use by 32-bit PCI devices, among other things.
With recent x86 processors it is now possible in fact for PCs to have more than 4GB of physical RAM, which means that RAM can extend further above 0xFFFFFFFF. In this case the BIOS must therefore arrange to leave a second hole in the system's RAM at the top of the 32-bit addressable region, in order to leave room for these 32-bit devices to be mapped. Because of design limitations JOS will actually be limited to using only the first 256MB of a PC's physical memory anyway, so for now we will pretend that all PCs still have "only" a 32-bit physical address space. But dealing with complicated physical address spaces and other aspects of hardware organization that evolved over many years is one of the important practical challenges of OS development.
Note the contents of the CS register in QEMU's info
registers output. It should read CS =f000 ffff0000 0000ffff
00000000. The ffff0000 is the segment base value, and
indicates that QEMU plans to execute an instruction at a very high
address.
To start QEMU, you'll connect to it using
GDB, the GNU debugger. In
the other terminal, and from your jos directory, enter
gdb. You should see something like this:
mug% gdb GNU gdb Red Hat Linux (6.6-16.fc7rh) Copyright (C) 2006 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux-gnu". + symbol-file obj/kernel Using host libthread_db library "/lib/libthread_db.so.1". + set architecture i8086 The target architecture is assumed to be i8086 + display/i $cs*16+$eip + target remote localhost:1234 0x0000fff0 in ?? () 1: x/i $cs * 16 + $eip 0xffff0: ljmp $0xf000,$0xe05b (gdb)
.gdbinit file that runs a couple important commands on
startup. Here's what they do:
symbol-file obj/kernel: Tells GDB to read symbols and debugging information from theobj/kernelfile.set architecture i8086: Tells GDB that the attached QEMU process starts out in 16-bit compatible mode.display/i $cs*16+$eip: Tells GDB to display the current instruction. The "$cs*16+$eip" expression is necessary for 16-bit compatible mode; in 32-bit mode, you would say "$pc".target remote localhost:1234: Attaches GDB to QEMU.
The following line:
1: x/i $cs * 16 + $eip 0xffff0: ljmp $0xf000,$0xe05b
is GDB's disassembly of the first instruction to be executed. Now type
si to step forward one instruction.
(gdb) si # "SI" means "Step Instruction"; it causes QEMU to execute one instruction.
0x0000e05b in ?? ()
1: x/i $cs * 16 + $eip 0xfe05b: xor %ax,%ax
Type info registers in the QEMU monitor and
note how the CS and EIP registers have changed. (You can scroll through
the QEMU monitor using Ctrl-PageUp and Ctrl-PageDown.)
From this output you can conclude a few things:
- 486 and later processors start executing at physical address 0xfffffff0, which is in an area reserved for the ROM BIOS.
- This instruction jumps to the normal BIOS, which is located in the
64KB region from 0xf0000 to 0xfffff mentioned above. (Why? We are
in real mode, so the
jmp farinstruction is a real mode jump that restores us to low memory.) The segmented address $0xf000,$0xe05b translates to 0x000fe05b in real mode.
Why does QEMU start like this? This is how Intel designed the 8088 processor, which IBM used in their original PC. Because the BIOS in a PC is "hard-wired" to the physical address range 0x000f0000-0x000fffff, this design ensures that the BIOS always gets control of the machine first after power-up or any system restart -- which is crucial because on power-up there is no other software anywhere in the machine's RAM that the processor could execute. QEMU comes with its own BIOS, which it maps at this location in the processor's simulated physical address space. On processor reset, the (simulated) processor sets CS to 0xf000 and the IP to 0xfff0, and pulls some trickery so the 486 BIOS at 0xfffffff0 runs first. This code immediately jumps to the original BIOS at 0xfe05b. But how did the segmented address 0xf000:e05b turn into the physical 0x000fe05b we mentioned above?
To answer that we need to know a bit about real mode addressing. In real mode (the mode that PC starts off in), address translation works according to the formula: physical address = 16 * segment + offset. So, when the PC sets CS to 0xf000 and IP to 0xfff0, the physical address referenced is:
16 * 0xf000 + 0xe05b # in hex multiplication by 16 is = 0xf0000 + 0xe05b # easy--just append a 0. = 0xfe05b
We can see that the PC starts executing 16 bytes from the end of the BIOS code. Therefore we shouldn't be surprised that the first thing that the BIOS does is jmp backwards to an earlier location in the BIOS; after all how much could it accomplish in just 16 bytes?
Exercise 2.
Use GDB's si command to trace into the ROM BIOS
for a few more instructions,
and try to guess what it might be doing.
You might want to look at the
Phil Storrs I/O Ports Description
as well as other materials on the
class reference materials page.
No need to figure out all the details --
just the general idea of what the BIOS is doing first.
|
After initializing the PCI bus and all the important devices the BIOS knows about, it searches for a bootable device such as a floppy, hard drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS reads the boot loader from the disk and transfers control to it.
Part 2: The Boot Loader
Floppy and hard disks for PCs are by historical convention divided up into 512 byte regions called sectors. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the boot sector, since this is where the boot loader code resides. When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through 0x7dff, and then uses a jmp instruction to set the CS:IP to 0000:7c00, passing control to the boot loader. Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it. For more information, see the "El Torito" Bootable CD-ROM Format Specification.
For class, however, we will use the conventional hard drive boot mechanism, which means that our boot loader must fit into a measly 512 bytes. The boot loader consists of one assembly language source file, boot/boot.S, and one C source file, boot/main.c Look through these source files carefully and make sure you understand what's going on. The boot loader must perform two main functions:
- First, the boot loader switches the processor from real mode to 32-bit protected mode, because it is only in this mode that software can access all the memory above 1MB in the processor's physical address space. Protected mode is described briefly in sections 1.2.7 and 1.2.8 of PC Assembly Language, and in great detail in the Intel architecture manuals. At this point you only have to understand that translation of segmented addresses (segment:offset pairs) into physical addresses happens differently in protected mode, and that after the transition offsets are 32 bits instead of just 16.
- Second, the boot loader reads the kernel from the hard disk by directly accessing the IDE disk device registers via the x86's special I/O instructions. If you would like to understand better what the particular I/O instructions here actually mean, check out the "IDE hard drive controller" section on the class reference page. You will not need to learn much about programming specific devices in this class: writing device drivers is in practice a very important part of OS development, but from a conceptual or architectural viewpoint it is also one of the least interesting.
After you understand the boot loader source code, look at the file obj/boot/boot.asm. This file is a disassembly of the boot loader that our GNUmakefile creates after compiling the boot loader. This disassembly file makes it easy to see exactly where in physical memory all of the boot loader's code resides, and makes it easier to track what's happening while stepping through the boot loader in QEMU.
You can set address breakpoints in GDB with the b
command. For example, b *0x7c00 sets a
breakpoint at address 0x7C00. Once at a breakpoint, you can continue
execution using the c and
si commands: c causes
QEMU to continue execution until the next breakpoint (or until you press
Ctrl-C in GDB), and si
N steps through the instructions N at a time.
To examine instructions in memory (besides the immediate next one to be
executed, which GDB prints automatically), you use the
x/i command. This command has the syntax
x/Ni ADDR, where N is the
number of consecutive instructions to disassemble and ADDR is the
memory address at which to start disassembling.
|
Exercise 3.
Set a breakpoint at address 0x7c00, which is
where the boot sector will be loaded.
Continue execution until that break point.
Trace through the code in boot/boot.S,
using the source code and the disassembly file
obj/boot/boot.asm to keep track of where you are.
Also use the x/i command in GDB to disassemble
sequences of instructions in the boot loader,
and compare the original boot loader source code
with both the disassembly in obj/boot/boot.asm
and GDB.
At some point in boot/boot.S, the processor
switches from 16-bit compatibility mode to 32-bit protected mode.
Read the code to find this point. When single-stepping past this
point, you must tell GDB about this switch by entering
" Trace into bootmain() in boot/main.c, and then into readsect(). Identify the exact assembly instructions that correspond to each of the statements in readsect(). Trace through the rest of readsect() and back out into bootmain(), and identify the begin and end of the for loop that reads the remaining sectors of the kernel from the disk. Find out what code will run when the loop is finished, set a breakpoint there, and continue to that breakpoint. Then step through the remainder of the boot loader. |
Be able to answer the following questions for yourself:
- At exactly what point does the processor transition from executing 16-bit code to executing 32-bit code?
- What is the last instruction of the boot loader executed, and what is the first instruction of the kernel it just loaded?
- How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
| Challenge! Make JOS boot under QEMU from a simulated CD-ROM. You will need to learn about the mkisofs utility and will have to modify the QEMU command line appropriately. |
|
Challenge!
Although the current JOS boot loader is very simple,
it's almost too big to fit the boot sector!
(The boot sector has room for 510 bytes of program, of which the
JOS boot loader uses 450 when compiled by gcc-4.1.1.)
Modern boot loaders often have many more features than JOS.
For example, they might let the user select a kernel to boot from
a list, or specify options to pass to the kernel.
How do they fit this into 510 bytes?
They don't -- fancy bootloaders are multi-stage bootloaders.
The 510-byte true boot loader in the first sector loads another more
complex bootloader into memory, and executes that.
Design and implement a multi-stage bootloader for JOS. For example, your bootloader might draw a pretty picture on the console, then jump to the regular bootloader, which waited for a key and then loaded the kernel. Or design a bootloader than could load one of multiple kernels. |
Loading the Kernel
We will now look in further detail at the C language portion of the boot loader, in boot/main.c. To make sense out of boot/main.c you'll need to know what an ELF binary is. When you compile and link a C program such as the JOS kernel, the compiler transforms each C source ('.c') file into an object ('.o') file containing assembly language instructions encoded in the compact binary format expected by the hardware. The linker then combines all of the compiled object files into a single binary image such as obj/kernel, which in this case is a binary in the ELF format, which stands for "Executable and Linkable Format".
Full information about this format is available in the ELF specification on our reference page, but you will not need to delve very deeply into the details of this format in this class. As a whole ELF is powerful and complex, but most of the complexity supports dynamic loading of shared libraries, which we won't need.
For purposes of this class, you can consider the contents of an ELF executable to be (mostly) just a short, fixed-length header with important loading information, followed by several program sections, which are just contiguous chunks of code or data intended to be loaded byte-for-byte into memory at a fixed, pre-computed address before transferring control to the program. The loader does nothing to the code or data at load time; it must be ready to go.
An ELF binary starts with a fixed-length ELF header, followed by a variable-length program header listing each of the program sections to be loaded. The C definitions for these ELF headers are located in inc/elf.h. The relevant sections for our purposes are named as follows:
- '.text': The text section holds the program's machine code.
- '.rodata': Data that is intended to be read-only, such as ASCII string constants produced by the C compiler. (We will not actually bother making this data read-only, however.)
- '.data': The data section holds the program's general (initialized) data, such as global variables that are declared in the program with initializers such as 'int x = 5;'.
These conventional section names obviously reflect the processor's viewpoint: anything that humans would consider "text", such as ASCII strings generated by the C compiler from string literals in the source code, will actually be found in the '.rodata' section.
While the linker is computing the memory layout of a program, it reserves memory space for all uninitialized global variables, such as 'int x;', in yet another, special section called '.bss' that immediately follows the data section in memory. Since this section is supposed to be "uninitialized", however -- or rather, initialized to a default value of all zeros, as required for all global variables in C -- there is no need to store its contents. Instead, the linker simply records the address and size of the bss section in the ELF program header along with the sizes of the other sections to be loaded, and leaves it to the loader (or in some cases the program itself) to zero the bss section.
You can display a full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
% i386-jos-elf-objdump -h obj/kernel
obj/kernel: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00001843 f0100000 f0100000 00001000 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .rodata 0000049c f0101844 f0101844 00002844 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
...
4 .data 00008548 f0109000 f0109000 0000a000 2**12
CONTENTS, ALLOC, LOAD, DATA
5 .bss 00000660 f0111560 f0111560 00012548 2**5
ALLOC
...
%
You will see other sections than the ones we listed above, but the others are not important for right now. Most of the others are to hold debugging information, which is typically included in the program's executable file but not actually loaded into memory by the program loader. (In JOS, as you'll see below, we use these sections a bit differently.)
Besides the section information, there is one more field in the ELF header that is important to us, named e_entry. This field holds the link address of the entry point in the program: the memory address in the program's text section at which the program is supposed to begin executing. You can see the entry point:
% i386-jos-elf-objdump -f obj/kernel
To examine memory in GDB, you use the x command
with different arguments. The
GDB
manual has full details. For now, it is enough to know that the recipe
x/Nx ADDR prints N
words of memory at ADDR. (Note that both 'x's in
the command are lowercase.)
Warning: The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
| Exercise 4. Reset the machine (exit QEMU/GDB and start them again). Examine the 8 words of memory at 0x00100020 at the point the BIOS enters the boot loader, and then again at the point the boot loader enters the kernel. Why are they different? What is there at the second breakpoint? (You do not really need to use QEMU to answer this question. Just think.) |
Link vs. Load Address
The load address of a binary is the memory address at which a binary is actually loaded. For example, the BIOS is loaded by the PC hardware at address 0xf0000. So this is the BIOS's load address. Similarly, the BIOS loads the boot sector at address 0x7c00. So this is the boot sector's load address.
The link address of a binary is the memory address for which the binary is linked. Linking a binary for a given link address prepares it to be loaded at that address. A program's link address in practice becomes subtly encoded within the binary in a multitude of ways, with the result that if a binary is not loaded at the address that it is linked for, things will not work.
In one sentence: the link address is the location where a binary assumes it is going to be loaded, while the load address is the location where a binary actually is loaded. It's up to us to make sure that they turn out to be the same.
Look at the -Ttext linker command in boot/Makefrag, and at the address mentioned early in the linker script in kern/kernel.ld. These set the link address for the boot loader and kernel respectively.
| Exercise 5. Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in boot/Makefrag to something wrong, run gmake clean, recompile, and trace into the boot loader again to see what happens. Don't forget to change it back afterwards! |
When object code contains no absolute addresses that "subtly encode" the link address in this fashion, we say that the code is position-independent: it will behave correctly no matter where it is loaded. GCC can generate position-independent code using the -fpic option, and this feature is used extensively in modern shared libraries that use the ELF executable format. Position independence typically has some performance cost, however, because it restricts the ways in which the compiler may choose instructions to access the program's data. We will not use position-independent code at all in this class, simply because we have no pressing need to.
Part 3: The Kernel
We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!) Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.Using segmentation to work around position dependence
Did you notice above that while the boot loader's link and load addresses match perfectly, there appears to be a (rather large) disparity between the kernel's link and load addresses? Go back and check both and make sure you can see what we're talking about.
Operating system kernels often like to be linked and run at very high virtual address, such as 0xf0100000, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the next lab. Most machines don't even have that much physical memory, however. (How much would it be exactly?)
Since we can't actually load the kernel at physical address 0xf0100000, we will use the processor's memory management hardware to map virtual address 0xf0100000 -- the link address at which the kernel code expects to run -- to physical address 0x00100000 -- where the boot loader actually loaded the kernel. This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM.
In fact, we will actually map the entire bottom 256MB of the PC's physical address space, from 0x00000000 through 0x0fffffff, to virtual addresses 0xf0000000 through 0xffffffff respectively. You should now be able to see why the JOS kernel is limited to using only the first 256MB of physical memory in a PC.
The x86 processor has two distinct memory management mechanisms that we could use to achieve this mapping: segmentation and paging. Both are described in full detail in the 80386 Programmer's Reference Manual or the IA-32 Developer's Manual, Volume 3. When the JOS kernel first starts up, we'll initially use segmentation to establish our desired virtual-to-physical mapping, because it is quick and easy -- and the x86 processor requires us to set up the segmentation hardware in any case, because it can't be disabled!
|
Exercise 6.
Use QEMU and GDB to trace into the JOS kernel,
and identify the exact point
at which the new virtual-to-physical mapping takes effect.
Then examine the Global Descriptor Table (GDT)
that the code uses to achieve this effect,
and make sure you understand what's going on.
Hint: If you want to start GDB in 32-bit mode
(because you plan to run until a breakpoint located in 32-bit
code), edit What is the first instruction after this point that would fail to work properly if this virtual-to-physical mapping wasn't in place? Comment out or otherwise intentionally "break" the segmentation setup code in kern/entry.S, trace into it, and see if you were right. |
Formatted Printing to the Console
Most people take functions like printf() for granted, sometimes even thinking of them as "primitives" of the C language. But in an OS kernel, all I/O of any kind that we do, we have to implement ourselves!
Read through kern/printf.c, lib/printfmt.c, and kern/console.c, and make sure you understand their relationship. It will become clear in later labs why the printfmt.c is located in the separate lib directory.
| Exercise 7. We have omitted a small fragment of code -- the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment. |
Be able to answer the following questions:
- Explain the interface between
printf.candconsole.c. Specifically, what function doesconsole.cexport toprintf.c, and how doesprintf.cuse that function? - Explain the following from
console.c:1 if (crt_pos >= CRT_SIZE) { 2 int i; 3 memcpy(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) << 1); 4 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++) 5 crt_buf[i] = 0x0700 | ' '; 6 crt_pos -= CRT_COLS; 7 } -
Trace the execution of the following code step-by-step:
int x = 1, y = 3, z = 4; cprintf("x %d, y %x, z %d\n", x, y, z);- First, in the call to
cprintf(), to what doesfmtpoint? To what doesappoint? - Second, list (in order of execution) each call to
cons_putc,va_arg, andvcprintf. Forcons_putc, list its argument as well. Forva_arg, list whatappoints to before and after the call. Forvcprintflist the values of its two arguments.
- First, in the call to
- Run the following code.
uint32_t i = 0x00646c72; cprintf("H%x Wo%s", 57616, &i);What is the output? Explain how this output is arrived out in the step-by-step manner of the previous exercise.The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set
ito in order to yield the same output? Would you need to change57616to a different value?Here's a description of little- and big-endian and a more whimsical description.
-
In the following code, what is going to be printed after
'y='? (note: the answer is not a specific value.) Why does this happen?cprintf("x=%d y=%d", 3); -
Let's say that GCC changed its calling convention so that it
pushed arguments on the stack in declaration order,
so that the last argument is pushed last.
How would you have to change
cprintfor its interface so that it would still be possible to pass it a variable number of arguments?
| Challenge! Enhance the console to allow text to be printed in different colors. The traditional way to do this would be to make it interpret ANSI escape sequences embedded in the text strings printed to the console, but you may use any mechanism you like. There is plenty of information on the references page and elsewhere on the web on programming the VGA display hardware. If you're feeling really adventurous, you could try switching the VGA hardware into a graphics mode and making the console draw text onto the graphical frame buffer. |
The Stack
In the final exercise of this lab, we will explore in more detail the way the C language uses the stack on the x86, and in the process write a useful new kernel monitor function that prints a backtrace of the stack: a list of the saved Instruction Pointer (IP) values that can be used to determine the exact context in which a particular piece of C code was called.
| Exercise 8. Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? Which "end" of this reserved area does the initial stack pointer point to? And finally, is the kernel protected against stack overflow? |
In C/C++ programs on the x86, both the esp (stack pointer) and ebp (base pointer) registers typically have special meanings. The stack pointer points to the current dividing point in the stack area between "free" stack space and "in use" stack space. Since the stack grows down on the x86 (and on most other processors), at a given time the stack pointer points to the first "in use" byte of the stack; everything below that location in the region reserved for the stack is considered "free". Pushing values onto the stack decreases the stack pointer, and popping values off the stack increases the stack pointer. Various x86 instructions, such as call are "hard-wired" to use the stack pointer register.
The ebp register, in contrast, is associated with the stack primarily by software convention. On entry to a C function, the function's prologue code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current esp value into ebp for the duration of the function. If all the functions in a program consistently obey this convention, then at any given point during the program's execution, it is possible to trace back through the stack by following the chain of saved ebp pointers and determining exactly what nested sequence of function calls caused this particular point in the program to be reached. This capability can be particularly useful, for example, when a particular function causes an assert failure or panic because bad arguments were passed to it, but you aren't sure who passed the bad arguments. With stack backtrace functionality, you can trace back and find the offending function.
| Exercise 9. To become familiar with the C calling conventions on the x86, find the address of the test_backtrace function in obj/kernel.asm, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of test_backtrace push on the stack, and what are those words? |
The above exercise should give you the information you need to implement a stack backtrace function, which you should call mon_backtrace(). A prototype for this function is already waiting for you in kern/monitor.c. You can do it entirely in C, but you may find the read_ebp() function in inc/x86.h useful. You'll also have to hook this new function into the kernel monitor's command list so that it can actually be invoked interactively by the user.
The backtrace function should display a listing of function call frames in the following format (note the numbers of spaces):
Stack backtrace: 0: ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 1: ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 ...
The first line printed reflects the currently executing function, namely mon_backtrace itself, the second line reflects the function that called mon_backtrace, the third line reflects the function that called that one, and so on. You should print all the outstanding stack frames, not just a specific number for example. By studying kern/entry.S you'll find that there is an easy way to tell when to stop.
Within each line, the ebp value indicates the base pointer into the stack used by that function: i.e., the position of the stack pointer just after the function was entered and the function prologue code set up the base pointer. The listed eip value is the function's return instruction pointer: the instruction address to which control will return when the function returns. The return instruction pointer typically points to the instruction after the call instruction (why?). Finally, the four hex values listed after args are the first four arguments to the function in question, which would have been pushed on the stack just before the function was called. If the function was called with fewer than four arguments, of course, then not all four of these values will be useful. (Why can't the backtrace code detect how many arguments there actually are? How could this limitation be fixed?)
| Exercise 10. Implement the backtrace function as specified above. When you think you have it working right, run gmake grade to see if its output conforms to what our grading script expects, and fix it if it doesn't. After you have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like. |
Linking
How did the kernel executable get that way? Why does it have those sections, and in that order?
Well, we told the linker exactly what to put in the kernel executable using a linker script. Take a look at our kernel linker script in kern/kernel.ld. After some initial setup code, you'll see section and symbol definitions like these:
.text : {
*(.text .stub .text.* .gnu.linkonce.t.*)
}
PROVIDE(etext = .); /* Define the 'etext' symbol to this value */
This tells the linker, GNU ld, to create a segment called
.text in the executable. This segment will contain all the
data from the object files' .text, .stub,
.text.*, and .gnu.linkonce.t.* segments, all of
which are used by the GNU C compiler for various types of read-only data.
(* is a wildcard that matches any name fragment.) The
PROVIDE statement defines a symbol as a particular address.
"." refers to the linker's current address; as the linker
works through the sections, it lays out code in linear order, and
"." always refers to the next address it'll use. Here, then,
etext is defined to the address immediately following the
.text segment. In C/C++ code, etext is declared as
"extern const char etext[];", to get access to this
address.
Exercise 11. Understand the linker
script. You may refer to the
GNU ld Command Language manual. How many new symbols are
defined by kernel.ld? Does read-only instruction data
have lower or higher addresses than read/write data? Why don't we
need a starttext symbol? |
Debugging
The .stab and .stabstr sections contain
debugging symbols in STAB (Symbol TABle) format. Normally, it doesn't make
sense to load debugging symbols into memory along with application code.
Debugging symbols are large and only useful when you're actually debugging
something. Debugging a kernel, however, is a special case! When the
kernel panics we need the debugging symbols already loaded and ready to go.
Therefore, our linker script forces GNU ld to mark the symbols as
allocatable, and debugging symbols are loaded into memory along with the
rest of the kernel.
A stab is a simple five-field, 12-byte record as follows:
struct Stab {
uint32_t n_strx; // index into string table of name
uint8_t n_type; // type of symbol
uint8_t n_other; // misc info (usually empty)
uint16_t n_desc; // description field
uintptr_t n_value; // value of symbol
};
The .stab section is an array of these records. The
n_strx field is an offset into the string table,
.stabstr. All string-table strings are null-terminated.
It's extremely useful to have some simple debugging information available when you're debugging your kernel, so in the rest of this lab, you'll build a trivial kernel debugger that uses these symbols. Your goal is to modify your backtrace function to print file, linenumber, and function name information as well as addresses. Here's the format you should use:
Stack backtrace:
0: ebp f0114f18 eip f010007b args 00000000 00000000 00000000 f0114f68
kern/init.c:32: test_backtrace+3b (1 arg)
1: ebp f0114f38 eip f0100068 args 00000000 00000001 f01017d0 f0114f88
kern/init.c:30: test_backtrace+28 (1 arg)
2: ebp f0114f58 eip f0100068 args 00000001 00000002 f01017d0 f0114fa8
kern/init.c:30: test_backtrace+28 (1 arg)
...
7: ebp f0114ff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00
kern/entry.S:79: <unknown>+0 (0 arg)
(1 arg) indicates that the function takes 1 argument. The
+NN after the function name reports how far the EIP is
into the function definition; it is a hexadecimal number. In this
backtrace, each symbolic name refers to the "eip" in the
stackframe above it. Since this value is a return address, each symbolic
line really refers to the stackframe below it, and the topmost
function (which corresponds to mon_backtrace itself) has no
symbolic printout. Feel free to add extra symbolic information for the
topmost stackframe -- but this is a bit more difficult than it appears!
You'll need to read the current EIP, which isn't directly accessible. (How
can you get it?)
| Exercise 12. Modify your stack
backtrace function to display, for each EIP, the function name,
source filename, and line number corresponding to that EIP in the
stabs. To help you we have provided you with
|
In debuginfo_eip, where do __STAB_* come from? This question has a long answer; to help you to discover the answer, here are some things you might want to do:
- look in the file kern/kernel.ld for __STAB_*
- run i386-jos-elf-objdump -h obj/kernel
- run i386-jos-elf-objdump -G obj/kernel to examine the stabs in human-readable format
- run i386-jos-elf-c++ -fno-exceptions -fno-rtti -nostdinc -O2 -fno-builtin -I. -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s
- see if the bootloader loads the symbol table in memory as part of loading the kernel binary
You will also want to understand the
STAB format. Use that link to go to a STAB reference. However, note
that STAB format has been used by many different system vendors for over 30
years! Each vendor extends STAB a bit differently to get what they want,
so the reference manual often talks about various extensions to the format.
Don't worry about these extensions or the hard cases! Use i386-jos-elf-objdump -G to see the simpler class of
stabs generated by our assembler and compiler, and support only those.
| Challenge! Extend the JOS kernel monitor into a more full kernel debugger. Use stabs debugging information to allow users to print the values of variables, set breakpoints on filename/linenumber pairs, and so forth. You may find this enhancement particularly useful for debugging in future labs. |
This completes the lab. Type gmake tarball in the jos directory and submit your solutions via CourseWeb.