Yield mechanisms
To return from a timer interrupt
(INT_IRQ + INT_TIMER in kernel.cc), the
kernel calls proc::yield_noreturn(). Change it to call proc::yield()
instead.
To return from a sys_yield system call
(the SYSCALL_YIELD case in
kernel.cc), the kernel calls proc::yield(). Change it to call
proc::yield_noreturn() instead.
Changing the timer interrupt to call proc::yield() is simple:
// this->regs_ = regs;
// this->yield_noreturn();
this->yield();
break;
There’s no need to store an explicit resume
point. When proc::exception returns (after this->yield() resumes and returns),
the interrupted process will resume.
To use proc::yield_noreturn() in SYSCALL_YIELD,
we must set the system call’s return value
by modifying regs explicitly. System calls, unlike general exceptions,
have return values, and it’s important to get them right.
// yield();
// return 0; -- sets reg_rax
this->regs_ = regs;
regs->reg_rax = 0;
this->yield_noreturn(); // NB does not return
// This comment will never be reached!
// This one either!
break;
A synchronization bug
What potential bug was addressed by commit d12e98cdb959bb9cdb85fc8e1b0878733026388e?
Describe a possible execution of the old code that could violate some
kernel invariant or otherwise cause a problem.
The old code violates a Chickadee invariant, which is that the currently
running process’s yields_ and regs_ can be set only when interrupts
are disabled and remain disabled until the next proc::yield_noreturn().
Violations of this invariant can cause lost wakeups and crashes.
A correct execution with nested resumption states
When a Chickadee context switch or exception occurs, Chickadee saves
resumption state on the relevant kernel task stack. Because kernel tasks
are suspendable, this resumption state can be nested. For example, this can
happen:
-
A process makes a system call. The architecture disables interrupts,
twiddles some registers, and jumps to syscall_entry.
-
syscall_entry saves regstate resumption state on the kernel task stack and calls
proc::syscall.
-
The system call implementation enables interrupts and later calls proc::yield.
-
proc::yield saves yieldstate resumption state on the stack.
-
Before it finishes, an interrupt occurs. The architecture disables
interrupts, pushes a partial regstate onto the kernel task stack, and
jumps to exception_entry.
If the exception had happened when the CPU was in unprivileged mode (in
user context), the CPU would have pushed the partial regstate onto the
CPU stack.
-
exception_entry completes the regstate, then calls proc::exception.
-
proc::exception calls proc::yield.
-
proc::yield saves yieldstate resumption state on the kernel task
stack.
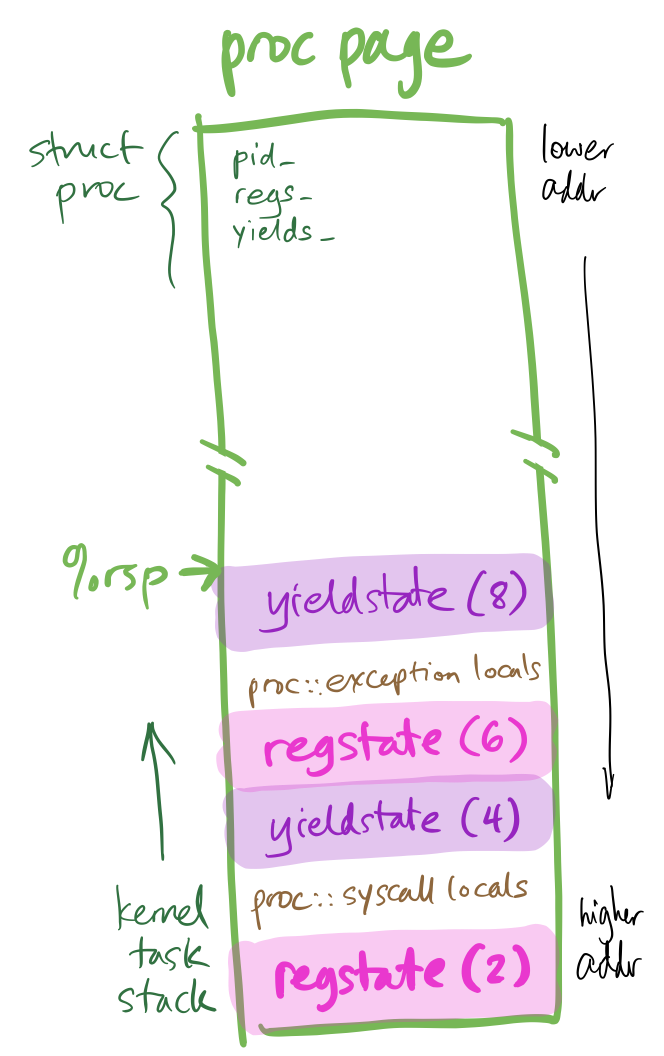
proc::yield stores a pointer to that yieldstate in the proc::yields_
member, disables interrupts, and switches to the cpustate stack.
Only in step 9 does the kernel change to another stack (first the CPU stack,
and then, potentially, another kernel task stack). That’s why step 9 stores
a pointer to the resumption state in a location independent of stack depth
(proc::yields_). Until step 9, %rsp and local variables suffice to tell
the kernel where to resume.
Later, when the kernel resumes the yielded process, steps 5–8 will be undone.
- (undoes 8)
proc::resume loads %rsp with the value stored in
proc::yields_, erases proc::yields_, pops callee-saved registers
from the on-stack yieldstate,
and executes the retq instruction.
- (undoes 7) That returns to
proc::exception. Assume
proc::exception then returns.
- (undoes 6) The second half of
exception_entry reloads registers from
the on-stack regstate and…
- (undoes 5) executes
iretq.
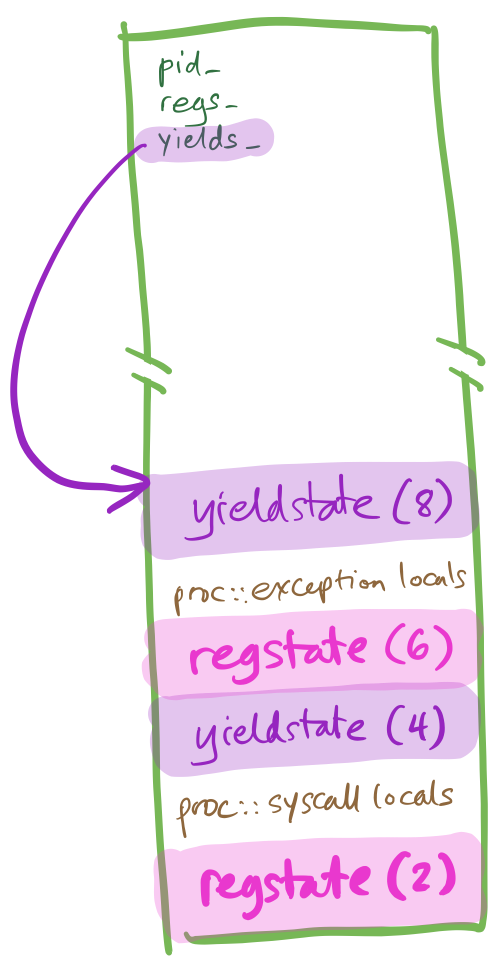
At this point, the proc::yield execution resumes. The process is going to
sleep again! This shouldn’t be a problem—and it isn’t.
proc::yield stores a pointer to the yieldstate in the
proc::yields_ member, disables interrupts, and switches to the
cpustate stack.
Later, when the kernel resumes the re-yielded process again, steps 1–4 are undone.
- (undoes 14 and 4)
proc::resume loads %rsp with the value
stored in proc::yields_, pops callee-saved registers, and executes
retq.
- (undoes 3) That returns to
proc::syscall. Assume proc::syscall then
returns.
- (undoes 2) The second half of
syscall_entry skips over the on-stack
regstate and…
- (undoes 1) executes
iretq.
And the process resumes.
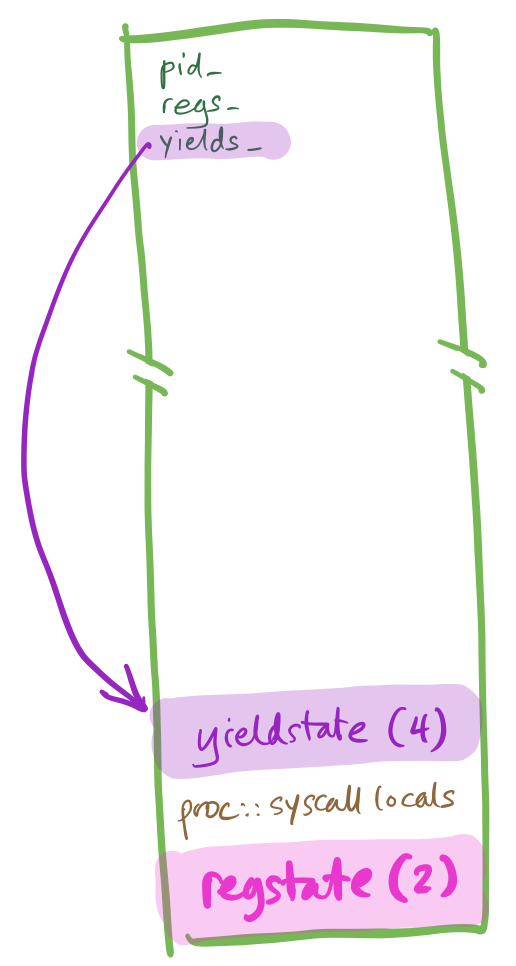
A problematic execution
This is the old yield code:
// store yieldstate pointer
movq %rsp, 16(%rdi)
// disable interrupts, switch to cpustack
cli
movq %rdi, %rsi
movq %gs:(0), %rdi
leaq CPUSTACK_SIZE(%rdi), %rsp
// call scheduler
jmp _ZN8cpustate8scheduleEP4proc
The problem triggers when an interrupt occurs immediately before cli.
exception_entry will store a regstate, and proc::exception will
execute, with yields_ set to a non-null value. That’s already weird, but things really
go wrong if proc::exception then calls proc::yield. The second proc::yield
call overwrites the stored yields_:
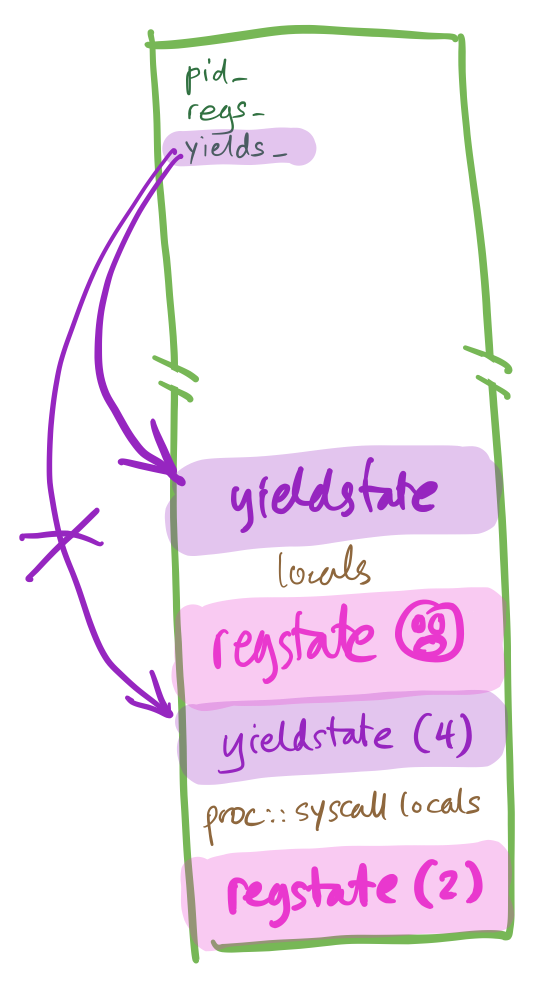
And the overwritten yields_ is never recovered.
Eventually there will be no place for the process to resume!

The fix
In the revised, correct implementation, yields_ is set after
interrupts are disabled. As a result, no exception will overwrite yields_
unexpectedly, and the process always resumes at the correct place.
Red zone
The Chickadee kernel must be compiled with the GCC flag -mno-red-zone, which
disables the x86-64 red
zone,
a feature of the System V AMD64 ABI (Application Binary
Interface).
Describe what the -mno-red-zone flag does, and why the Chickadee kernel must
be compiled with that flag.
The -mno-red-zone prevents the compiler from using the red zone for kernel
functions, so kernel functions will never access data at negative offsets
from %rsp. This is important because of interrupts. If a kernel task runs
with interrupts enabled and an interrupt occurs, the processor’s interrupt
mechanism stores the five critical registers immediately below the active
%rsp. This would irretrievably overwrite any data the compiler stored in
the red zone.
Processor affinity and CPU migration
Multiprocessor operating systems support notions of processor affinity and
CPU migration, in which tasks (including process threads and kernel tasks)
switch from processor to processor as they run. This can be important for load
balancing—maybe all the threads on processor 0 happen to exit at about the
same time, leaving processor 0 idle and the other processors oversubscribed—so
a good kernel scheduler will proactively migrate tasks to mitigate this
imbalance. There are also system calls that manage CPU placement directly,
such as sched_setaffinity.
But moving a task from one CPU to another is harder than it might appear,
because of synchronization invariants. It’s especially difficult
because at the same moment as a kernel task is changing its affinity from
one CPU to another, a different task might be trying to schedule the first
task on its original home CPU!
Design a system-call-initiated CPU migration for Chickadee. Specifically,
describe the implementation of a sys_sched_setcpu(pid_t p, int cpu) system
call, which should work as follows:
-
If p != 0 && p != current()->id_, then return an EPERM error (you’ll
fix this in the next exercise).
-
If cpu < 0 || cpu >= ncpu, then return an EINVAL error.
-
Otherwise, the system call returns 0 and the calling thread (process) next
executes on CPU cpu. That is, when the system call returns 0, the
unprivileged process code is executing on CPU cpu.
The difficulty here is the relationship between per-CPU run queue locks and
per-kernel-task home CPUs. The per-task home CPU value, proc::runq_cpu_,
is used to look up the relevant per-CPU run queue lock,
cpustate::runq_lock_. So although it’s tempting to protect
proc::runq_cpu_ with cpustate::runq_lock_, this just doesn’t work—it’s a
circular dependency!
A partial solution is to add a new per-task lock, proc::runq_cpu_lock_,
that must be acquired before accessing proc::runq_cpu_. But even that
risks violating other scheduling invariants. What if process 1 running on
CPU 1 changes its runq_cpu_ to 2, and then, before process 1 can yield,
some other process schedules it using proc::unblock()? There’s a chance
that code running on behalf of process 1 would execute on CPUs 1 and 2
simultaneously—a disaster.
To complete the solution, we need to change runq_cpu_ only in a location
where the kernel task is known to not be running. Namely,
cpustate::schedule. We add a new member, proc::desired_runq_cpu_, that
cpustate::schedule can check before changing a proc’s true runq_cpu_.
Migrating other processes
Extend your sys_sched_setcpu design so processes can change
other processes’ CPU placements (that is, support p != 0 && p != current()->id_). Again, your implementation must obey all Chickadee
invariants and should not cause undefined behavior.
Our design of this feature does not add any new proc members, but it does
add new invariants, and it changes one of the invariants we added above.