Ticket lock
struct ticket_lock {
std::atomic<unsigned> now_ = 0;
std::atomic<unsigned> next_ = 0;
void lock() {
unsigned me = next_++;
while (me != now_) {
pause();
}
}
void unlock() {
now_++;
}
};
- Problems with ticket lock?
MCS (Mellor-Crummey Scott) lock
- Early high-performance fair lock, good at high contention
- Data structure: A queue of waiting threads, implemented as a singly-linked
list
- Shared lock points at the tail of the list (the thread that will get
the lock last, if any)
- Threads spin not on shared state, but on local state, which makes
spinning much cheaper (no hammering the cache coherence protocol)
- Used widely in Java and now Linux
- Link; Shorter earlier version
MCS lock I (guard-style)
struct mcs_lock {
std::atomic<mcs_lock_guard*> tail_; // nullptr if unlocked
};
struct mcs_lock_guard { // represents a thread waiting for/holding lock
std::atomic<mcs_lock_guard*> next_ = nullptr;
std::atomic<bool> blocked_ = false;
mcs_lock& lock_;
mcs_lock_guard(mcs_lock& lock)
: lock_(lock) { // lock
mcs_guard* prev_tail = lock_.tail_.exchange(this); // mark self as tail
if (prev_tail) { // must wait for previous tail to exit
blocked_ = true;
prev_tail->next_ = this;
while (blocked_) {
pause();
}
}
}
~mcs_lock_guard() { // unlock
if (!next_) {
mcs_lock_guard* expected = this;
if (lock_.compare_exchange_strong(expected, nullptr)) {
return;
}
}
while (!next_) {
pause();
}
next_->blocked_ = false;
}
};
// some function that uses a lock `l`
f() {
...
{
mcs_lock_guard guard(l);
... critical section ...
}
...
}
About MCS
- Much more overhead!
- Atomic operations and spins in both lock and unlock
- Higher latency, lower throughput
- Relatively high space overhead
- Advantages to this overhead
- Fairness
- Each waiter is spinning on private state, not shared state!
- Fewer cache line conflicts
- How does it work?
- If atomic swap (
std::atomic<T>::exchange) in lock returns non-nullptr,
w is appended to linked list and spins until it is notified that it is no
longer locked.
unlock waits until there is a next waiter in the list, and unlocks it.
- MCS lock is optimized for high contention, but in that case you already have
performance issues.
Variants of MCS
- The MCS queue is ordered by arrival time
- What other orders might be useful?
- Performance improves when cache lines aren’t contended
- Some cores are “closer” than others (share caches)
- Maybe order by distance!
ShflLocks
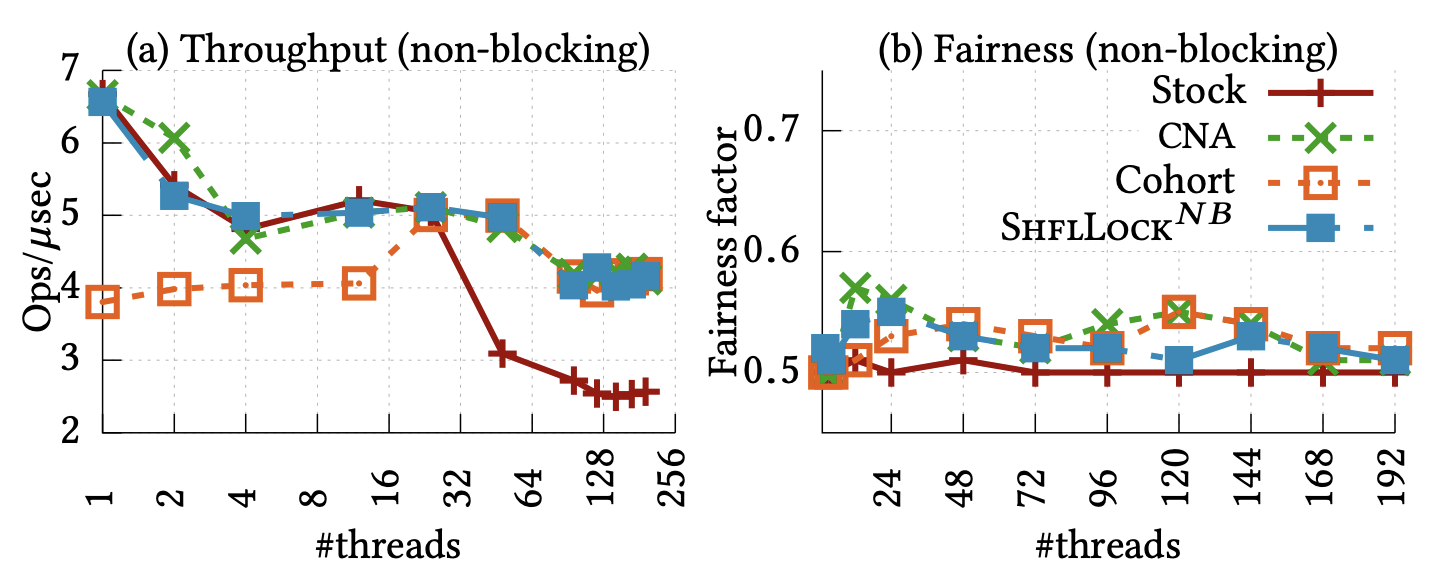
Beyond shuffling
- Shuffling means cache lines travel less
- What’s the endpoint of this line of thinking?
- Maybe cache lines should not travel at all
- Instead of moving shared data structure to the computation, move the
computation (plus arguments) to the data
Delegation
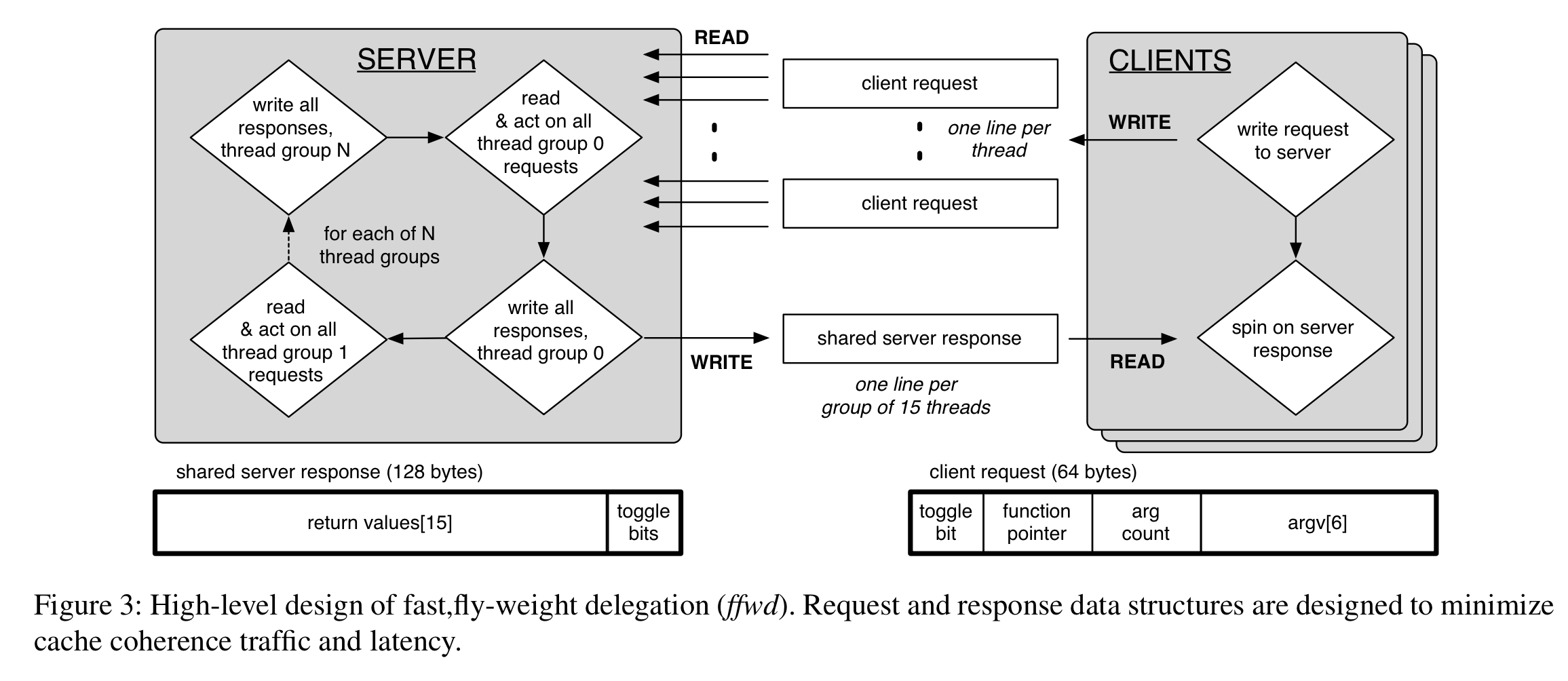
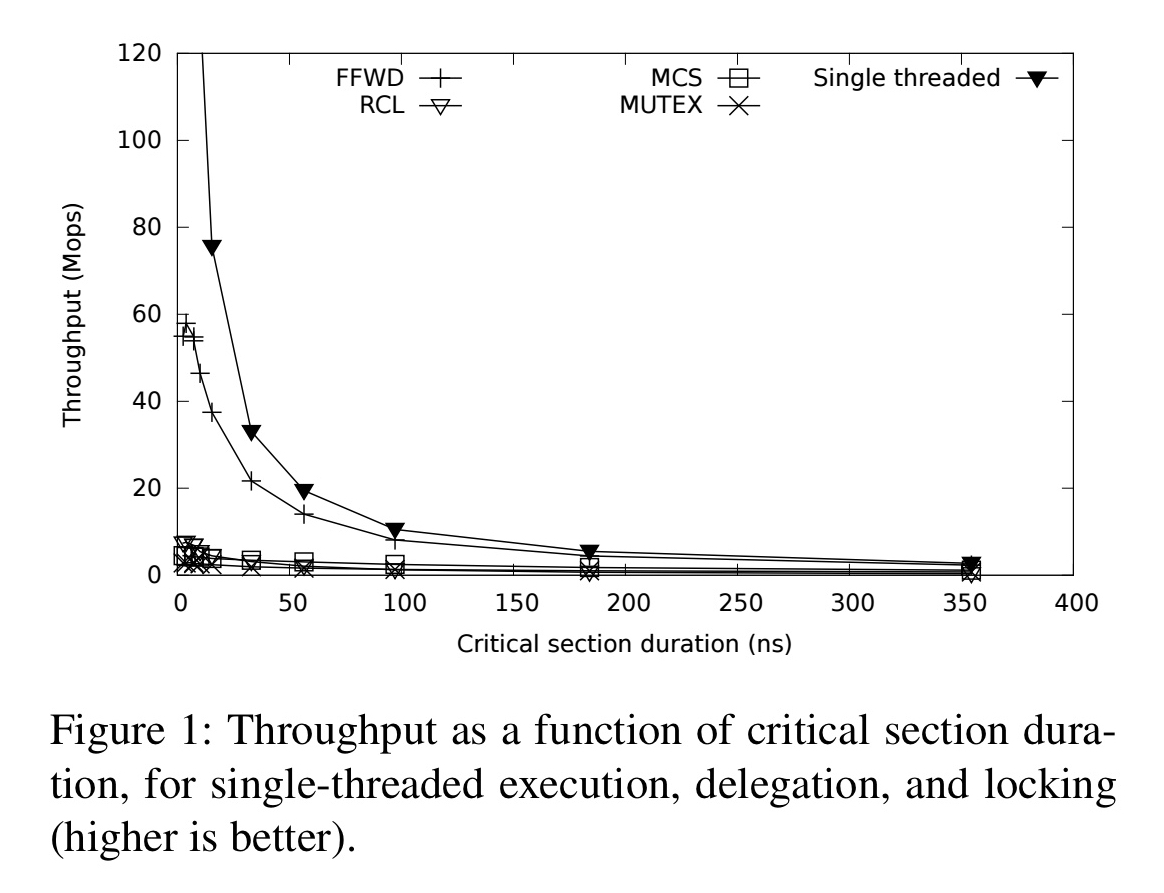
Readers/writer locks
- Data structure readers can often run in parallel (because they don’t modify a structure)
- A readers/writer lock allows one or more concurrent readers, or a single writer
- Good when reads are much more common than writes
Readers/writer implementation
- Three lock states
- unlocked (
val_ == 0)
- read locked (
val_ > 0)
- write locked (
val_ == -1)
struct rw_lock {
std::atomic<int> val_;
void lock_read() {
int expected = val_;
while (expected < 0
|| !val_.compare_exchange_weak
(expected, expected + 1)) {
pause();
expected = val_;
}
}
void unlock_read() {
--val_;
}
void lock_write() {
int expected = 0;
while (!val_.compare_exchange_weak(expected, -1)) {
pause();
expected = 0;
}
}
void unlock_write() {
val_ = 0;
}
};
rwlock variant: Reduce memory contention
- Give each thread its own
val_
struct rw_lock_2 {
spinlock f_[NCPU]; // would really want separate cache lines
void lock_read() {
f_[this_cpu()].lock();
}
void unlock_read() {
f_[this_cpu()].unlock();
}
void lock_write() {
for (unsigned i = 0; i != NCPU; ++i) {
f_[i].lock();
}
}
void unlock_write() {
for (unsigned i = 0; i != NCPU; ++i) {
f_[i].unlock();
}
}
};
- This makes reads fast and writes fairly slow
rwlock variant: Fairness
struct ticket_rwlock {
std::atomic<unsigned> now_ = 0;
std::atomic<unsigned> read_now_ = 0;
std::atomic<unsigned> next_ = 0;
void read_lock() {
unsigned me = next_++;
while (me != read_now_) {
pause();
}
read_now_++;
}
void read_unlock() {
now_++;
}
void write_lock() {
unsigned me = next_++;
while (me != now_) {
pause();
}
}
void write_unlock() {
read_now_++;
now_++;
}
};