February 9 — by April Chen & Zev Nicolai-Scanio
- “TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems”, Abadi M, Agarwal A, Barham P, Brevdo E, et al. (2015) (link)
- “Dask: Parallel Computation with Blocked algorithms and Task Scheduling”, Rocklin M (2015) (link)
- “A performance comparison of Dask and Apache Spark for data-intensive neuroimaging pipelines”, Dugré M, Hayot-Sasson V, Glatard T (2019) (link)
Thoughts on the Tensorflow whitepaper?
- General reactions?
- Discussion question from Canvas: TF is designed to be able to run on a single process, a single machine with multiple devices, and across multiple machines. What design features make this possible? Do they have any drawbacks compared to systems purely for multiple machines?
- Any additional thoughts, questions, queries, qualms, quandaries?
Thoughts on the Dask and Dask vs Spark papers?
- General reactions?
- Discussion question from Canvas: Read Section IIB, Infrastructure, carefully. Does anything surprise you about the deployment infrastructure? How does this infrastructure differ from the target infrastructures we've seen in other papers?
- Additional question: How would you characterize the workload evaluated in the Dugré et al. performance comparison paper? How does this workload differ from the target workloads we've seen in other papers?
- Any additional thoughts, questions, queries, qualms, quandaries?
Discussion ideas
-
How does Tensorflow address the issue of flexible consistency and the trade-off between system efficiency and convergence rates?
-
TF claims to build on timely dataflow and parameter server ideas. Are there any aspects of timely dataflow and/or parameter server that appear missing from TF? Why might TF have left off those features?
-
What are the differences between how Dask and TF assign nodes of their compute graphs to resources? What might be the advantages and disadvantages of the different systems?
-
Dask is a Python system that implements its graph structure in Python itself. In fact users can make their own graphs directly as Python dictionaries as opposed to using Dask objects that automatically generate them. What are the pros and cons of this design?
-
Dask and Tensorflow (and Spark) all use lazy evaluation for their compute graphs. Why do you think lazy evaluation is a dominant paradigm? Are there any cases you can think of where lazy evaluation might be a bad idea?
-
Compare machine learning applications across the papers we’ve read so far. For which problems would you expect Dask and Spark to have significantly different performance?
Takeaways: TensorFlow
- Placement algorithm
- Partial execution of subgraphs
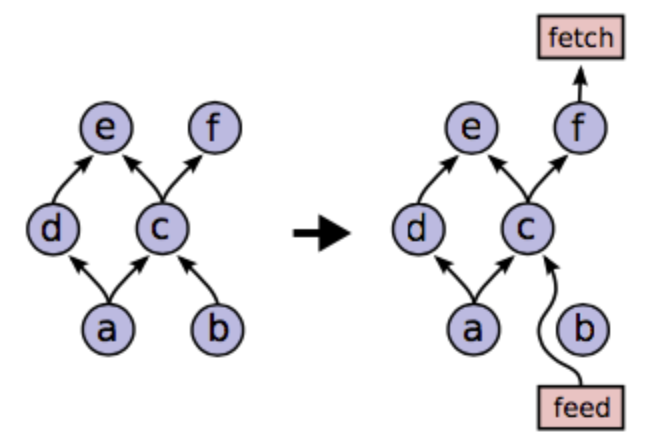
- Control flow
- Queues
- Containers
- EEG and the ability to reconstruct execution at detail
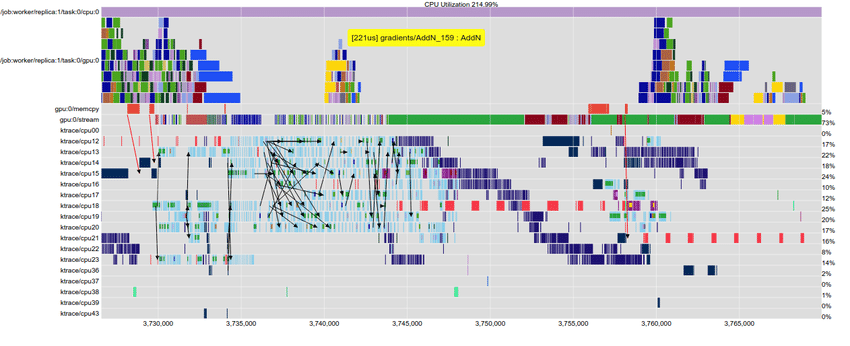
Takeaways: Dask
- Goal: take advantage of advances in hardware to parallelize the scientific python stack
- Dask graphs -- representing the program structure explicitly as Python objects
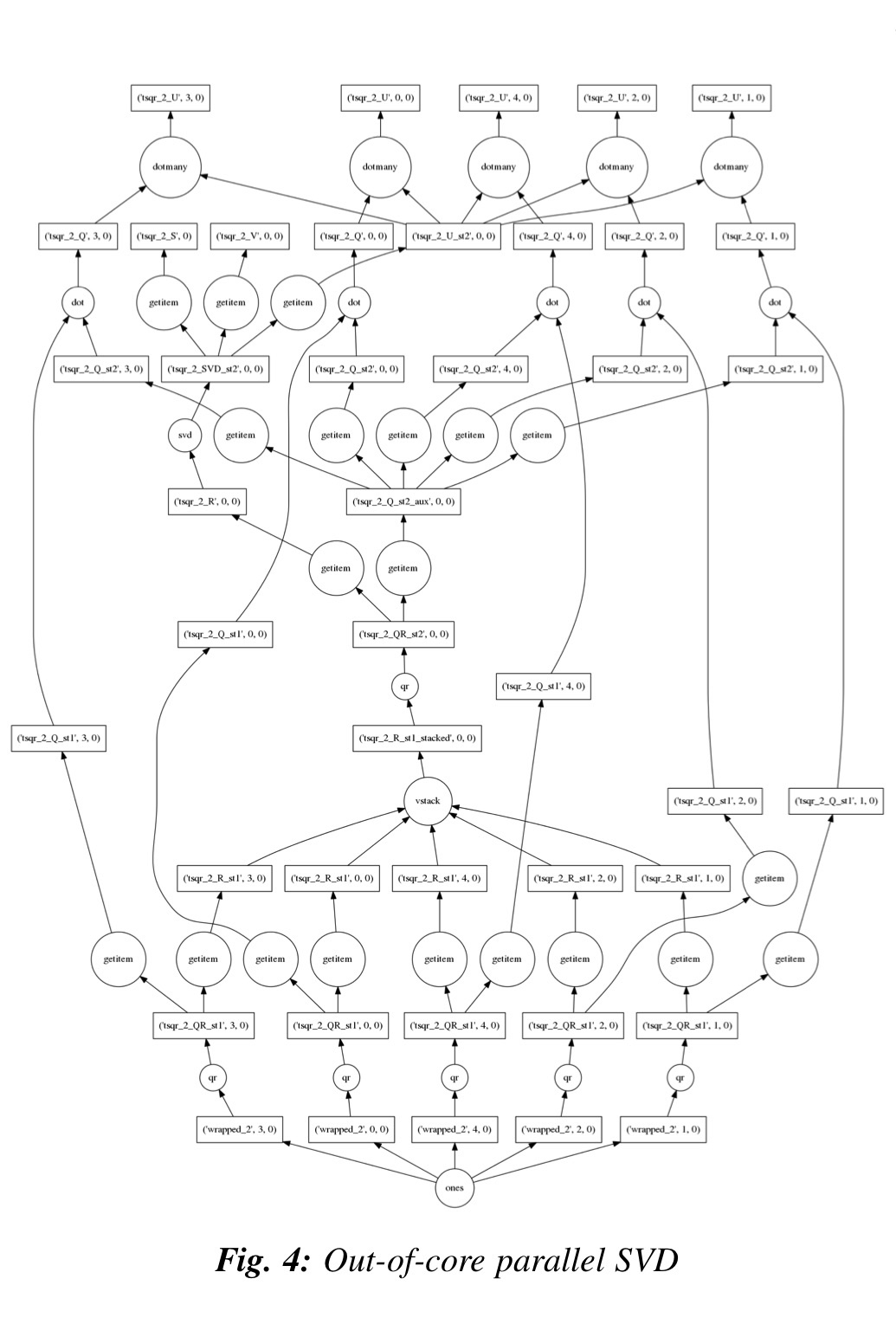
- Blocked array algorithms
- Independence of graph and scheduler
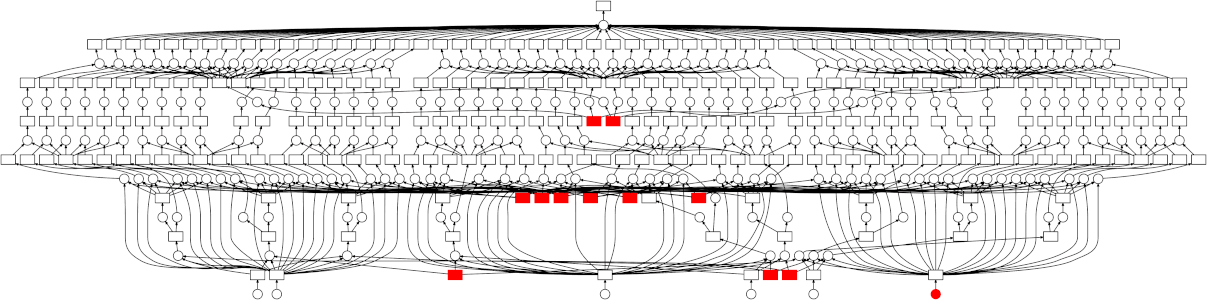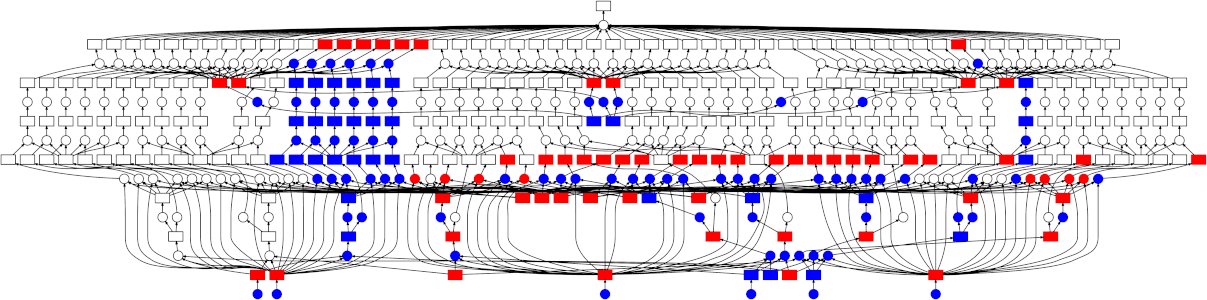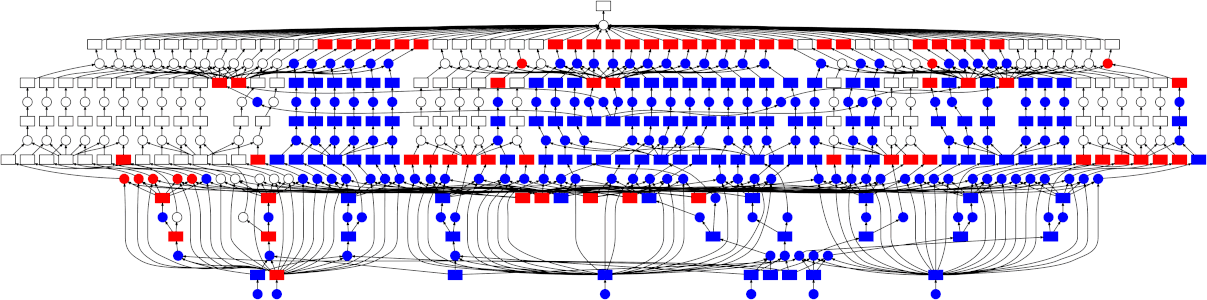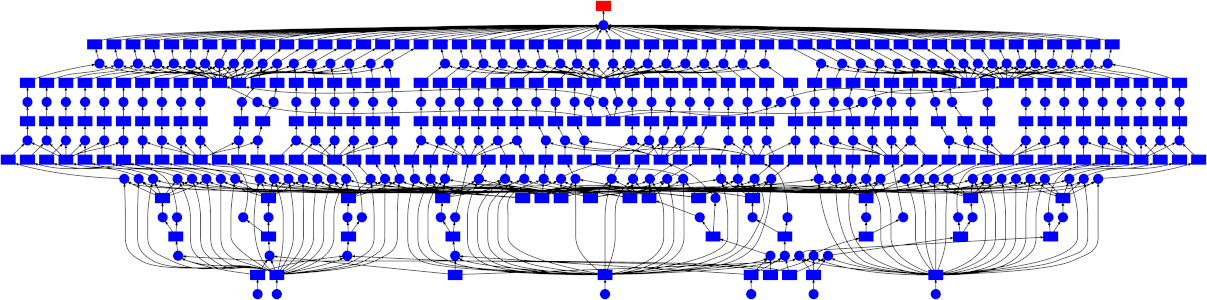
Dask vs. Spark
- Found no significant difference in this particular application case
- Disk bandwidth limitations -> overhead offsets data transfer time
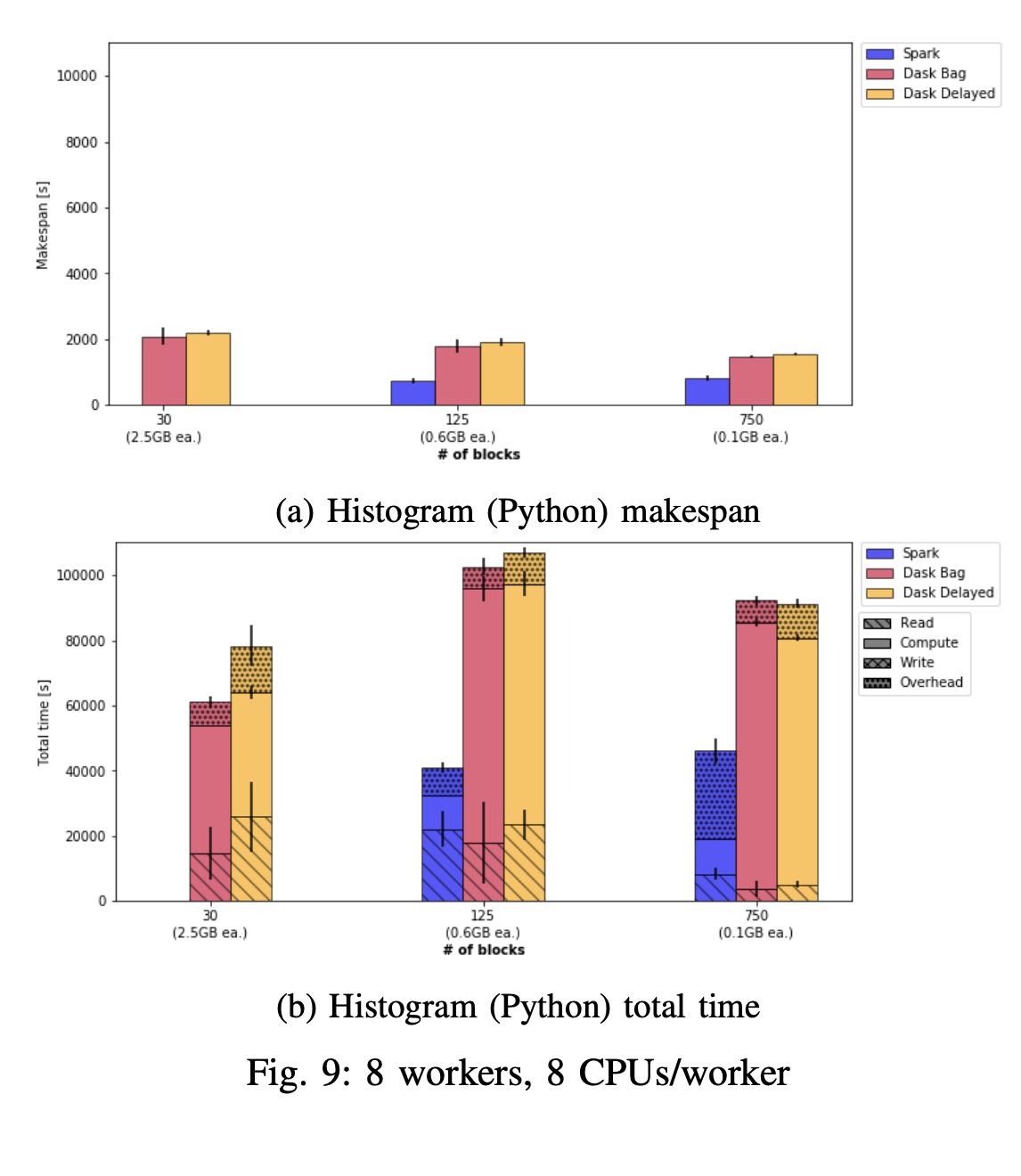
- Python Global Interpreter Lock
- Fewer data partitions reduce overhead, more partitions increase parallelism