System calls are expensive for several reasons, particularly on modern
processors.
For the past 30+ years, system calls have been the de facto
interface used by applications to request services from the
operating system kernel. System calls have almost universally
been implemented as a synchronous mechanism,
where a special processor instruction is used to yield userspace
execution to the kernel. In the first part of this
paper, we evaluate the performance impact of traditional
synchronous system calls on system intensive workloads.
We show that synchronous system calls negatively affect
performance in a significant way, primarily because of
pipeline flushing and pollution of key processor structures
(e.g., TLB, data and instruction caches, etc.).
…
System call invocation typically
involves writing arguments to appropriate registers and
then issuing a special machine instruction that raises a
synchronous exception, immediately yielding user-mode
execution to a kernel-mode exception handler. Two important
properties of the traditional system call design are
that: (1) a processor exception is used to communicate
with the kernel, and (2) a synchronous execution model is
enforced, as the application expects the completion of the
system call before resuming user-mode execution. Both of
these effects result in performance inefficiencies on modern
processors.
The increasing number of available transistors on a chip
(Moore’s Law) has, over the years, led to increasingly
sophisticated processor structures, such as superscalar
and out-of-order execution units, multi-level caches, and
branch predictors. … Server
and system-intensive workloads, which are of particular
interest in our work, are known to perform well below the
potential processor throughput. Most studies
attribute this inefficiency to the lack of locality. We claim
that part of this lack of locality, and resulting performance
degradation, stems from the current synchronous system
call interface.
Synchronous implementation of system calls negatively
impacts the performance of system intensive workloads,
both in terms of the direct costs of mode switching and,
more interestingly, in terms of the indirect pollution of
important processor structures which affects both usermode
and kernel-mode performance. A motivating example
that quantifies the impact of system call pollution
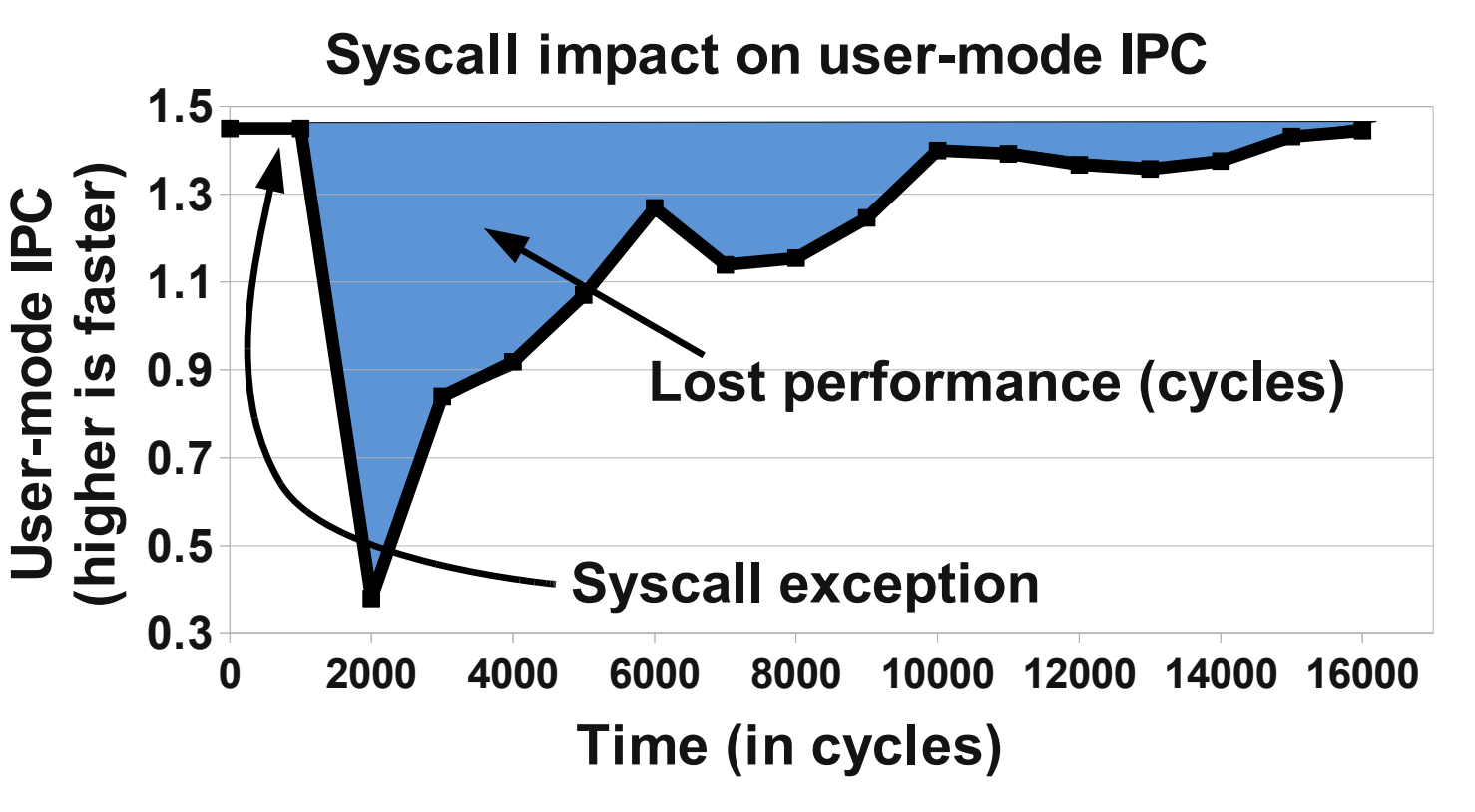
on application performance can be seen [below].
It depicts the user-mode instructions per cycles (kernel cycles and
instructions are ignored) of one of the SPEC CPU 2006 benchmarks (Xalan)
immediately before and after a pwrite system call. There is a significant
drop in instructions per cycle (IPC) due to the system call, and it takes up
to 14,000 cycles of execution before the IPC of this application returns to
its previous level. As we will show, this performance degradation is mainly
due to interference caused by the kernel on key processor structures.
Brainstorm some ways to reduce system call costs! Are there classes of
application, or system call usage patterns, for which a different system call
interface could outperform the normal synchronous system call interface? Are
there interface changes to specific system calls that could improve overall
application performance?
The quote above is from a paper (see the source below) that addresses the
system call performance problem in one specific way. Feel free to look at the
paper after brainstorming for a while yourselves.
“FlexSC: Flexible System Call Scheduling with Exception-Less
System Calls.” Livio Soares and Michael Stumm. In Proc. OSDI 2010. Link
These are general invariants, independent of the Chickadee file system design.
List as many Chickadee-specific invariants as you can, referring to the
structures declared in chickadeefs.hh. A few to get you started:
superblock::magic == chickadeefs::magic
superblock::fbb_bn < superblock::inode_bn
Use pseudocode or words. There are probably more than a hundred invariants you
could list! The more you list, the better you understand the file system.