General questions for research papers (1)
- What core problems were these works trying to solve?
- What system features targeted those core problems?
- Did the systems have other features, not targeted at core problems? What were they?
- Are those core problems still relevant today?
- Are the proposed solutions still relevant today?
General questions for research papers (2)
- Is this a good paper?
- What were the authors’ goals?
- What were the performance metrics?
- Did they convince you that this was a good system?
- Were there any red flags?
- What mistakes did they make?
- Does the system meet the “Test of Time” challenge?
- How would you review this paper today?
John Kubiatowicz’s rubric, seen for example in Advanced Topics in Computer Systems, ©2021 UCB
About these papers
- These papers were published as research papers—as a technical report, or in the Supercomputing conference—but research papers come in different varieties. These papers describe systems that the audience already knew about and already knew were useful.
What did MPI programs look like?
/*
* MPI Developers Conference 96
* http://www.cse.nd.edu/mpidc95/
* University of Notre Dame
*
* MPI Tutorial
* Lab 4
*
* Mail questions regarding tutorial material to mpidc@lsc.cse.nd.edu
*/
#include
#include "mpi.h"
/*
* Local function
*/
void Build_Matrix(int x, int y, MPI_Comm comm_in, MPI_Comm *comm_matrix,
MPI_Comm *comm_row, MPI_Comm *comm_col);
/*
* Global variables to make example simpler
*/
int rank, size, row, col;
int main(int argc, char **argv)
{
int x, y;
int sum_row, sum_col;
MPI_Comm comm_matrix, comm_row, comm_col;
/* Start up MPI */
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
/* Invoke for a hard-coded X and Y value. */
x= 2;
y= 2;
/* Print some output on the "console" process */
if (rank == 0)
printf("For a %dx%d matrix (size %d):\n", x, y, size);
/* Call the function to build the communicators */
Build_Matrix(x, y, MPI_COMM_WORLD, &comm_matrix, &comm_row, &comm_col);
/* Perform the reductions */
MPI_Allreduce(&rank, &sum_row, 1, MPI_INT, MPI_SUM, comm_row);
MPI_Allreduce(&rank, &sum_col, 1, MPI_INT, MPI_SUM, comm_col);
printf("Process (%d, %d): Row sum = %d, Col sum = %d\n", row, col,
sum_row, sum_col);
/* Quit */
MPI_Finalize();
return 0;
}
/*
* Build_Matrix(int, int, MPI_Comm, MPI_Comm *, MPI_Comm *, MPI_Comm *)
* Build the matrix, return the specified communicators
*/
void Build_Matrix(int x, int y, MPI_Comm comm_in, MPI_Comm *comm_matrix,
MPI_Comm *comm_row, MPI_Comm *comm_col)
{
/* Real (i.e. non-example) programs should obviously have */
/* have better recovery methods */
if (x * y != size) {
if (rank == 0)
printf("Sorry, program compiled for %dx%d matrix. Please run with %d processors.\n", x, y, x*y);
MPI_Finalize();
exit(-1);
}
/* Setup the args for MPI_Comm_split() */
row= rank / y;
col= rank % y;
/* Make the communicators. First duplicate comm_in (which */
/* in this case is MPI_COMM_WORLD) into comm_matrix. Then */
/* split comm_in again to create communicators for the row */
/* and column by assigning the color of the splitting to be */
/* the row and column numbers that we just calculated. */
MPI_Comm_dup(comm_in, comm_matrix);
MPI_Comm_split(comm_in, row, rank, comm_row);
MPI_Comm_split(comm_in, col, rank, comm_col);
}
MPI communication implementation
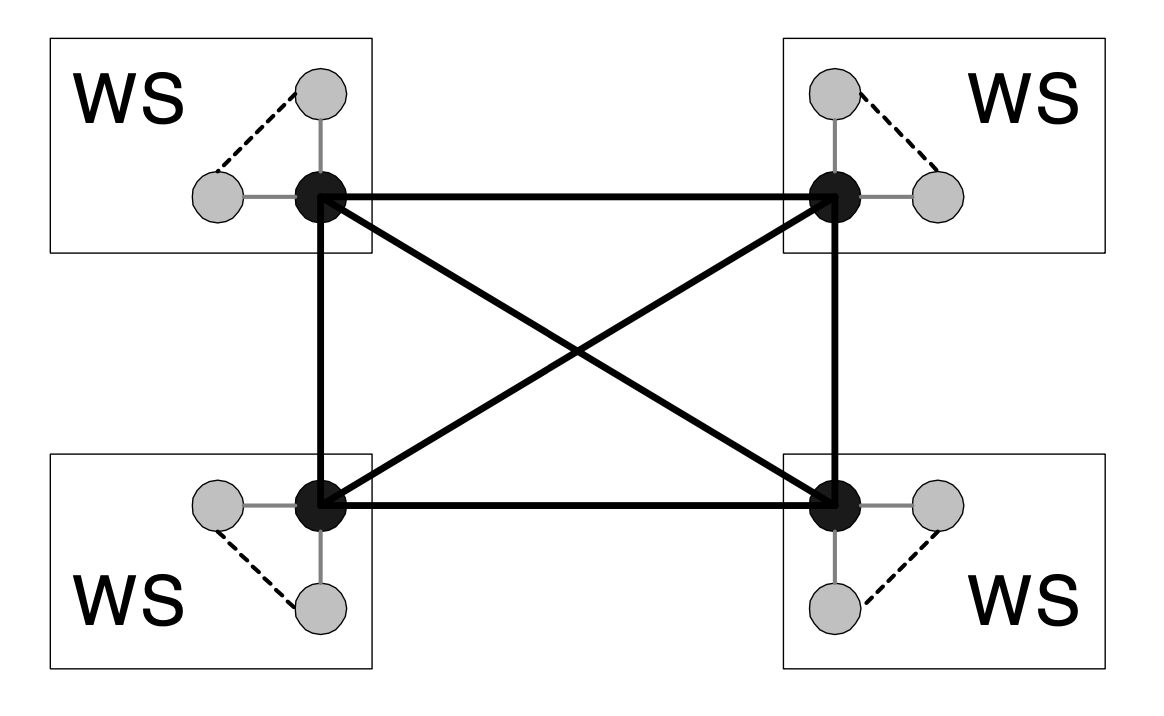
- MPICH: shared-memory communication on the same node, TCP/IP communication mediated by “daemon processes” across nodes
- Despite the authors’ discussion of “a message-passign standard” that “vendors…could implement efficiently at a low level, or even provide hardware support for in some cases”, few hardware implementations arose * “[MPI’s] functions are normally implemented in software due to their enormity and complexity, thus resulting in large communication latencies.” ref
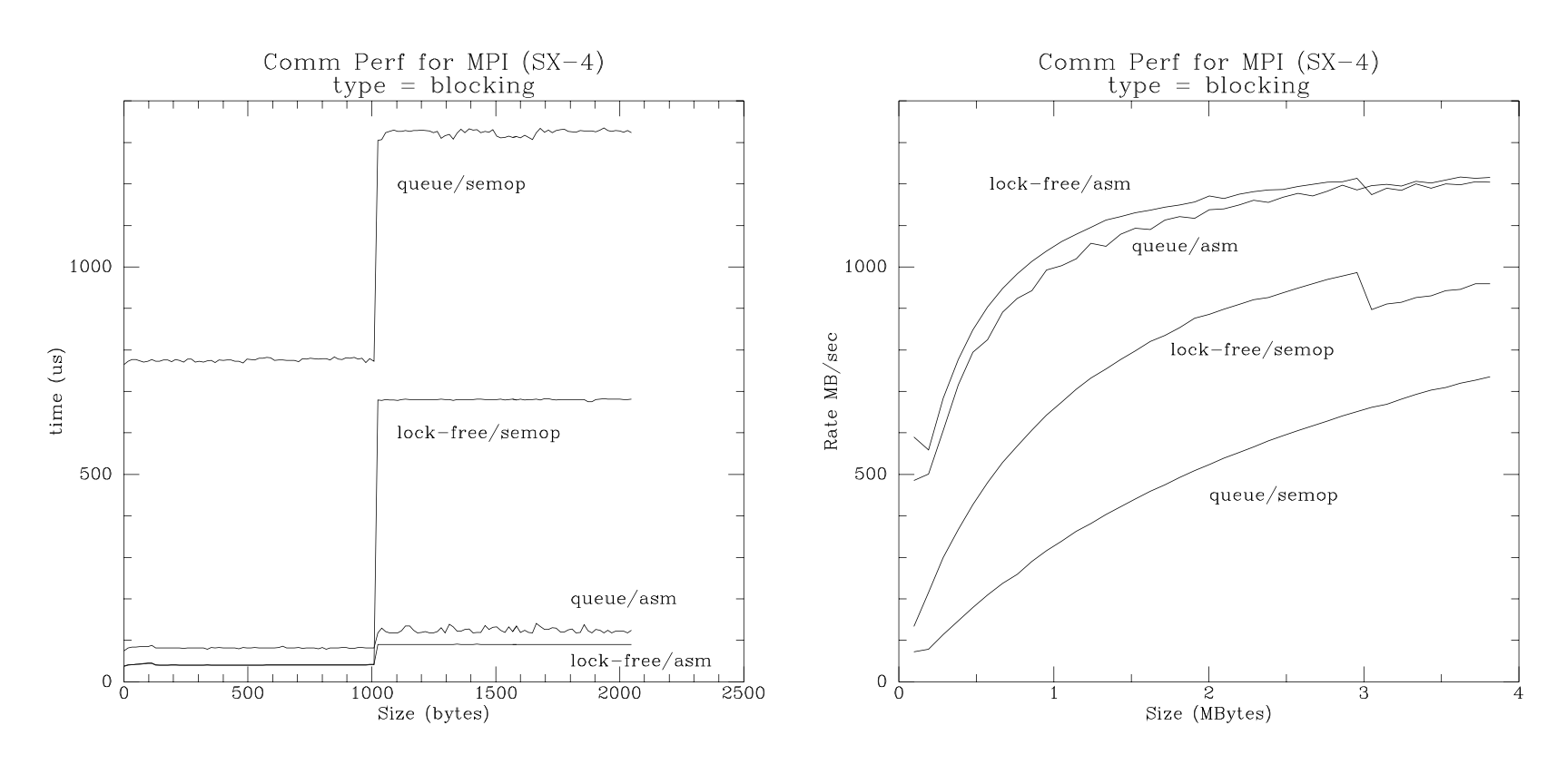
Optimization for fancy machines (1997)

Link (an open TR is also available)
Results
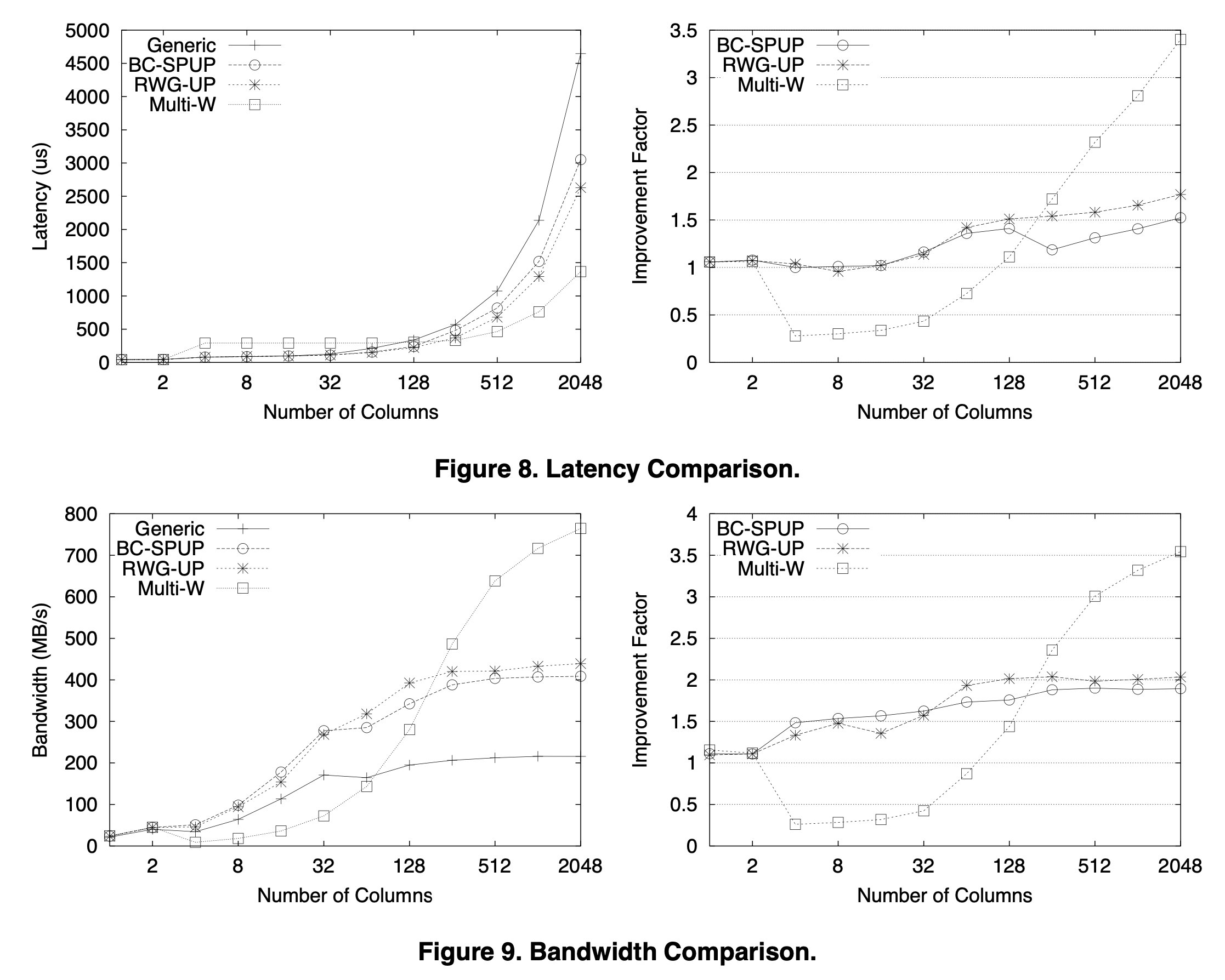
Optimization for fancy machines (2003)

Results
What did p4 programs look like?
#include "p4.h"
main(argc,argv)
int argc;
char **argv;
{
p4_initenv(&argc,argv);
p4_create_procgroup();
worker();
p4_wait_for_end();
}
worker()
{
char *incoming, *msg = "hello";
int myid, size, nprocs, from, i, type;
myid = p4_get_my_id();
nprocs = p4_num_total_ids();
for (i=0; i < nprocs; i++)
{
if (i != myid)
p4_send(100, i, msg, strlen(msg)+1);
}
for (i=0; i < nprocs - 1; i++)
{
type = -1;
from = -1;
incoming = NULL;
p4_recv(&type,&from,&incoming,&size);
printf("%d received msg=:%s: from %d",myid,incoming,from);
p4_msg_free(incoming);
}
}
Source: P4 manual
“We have nprocs slaves with ids 0, …, nprocs - 1. And, we want to write a
program in which every process sends a single message to every other slave,
and then receives a message from every other slave.”
Monitors
p4_menter(p4_monitor_t* m): Obtain the lock onmp4_mexit(p4_monitor_t* m): Release the lock onmp4_mdelay(p4_monitor_t* m, int i): Like condition variable wait: release the lock onm, sleep on theith queue of monitormp4_mcontinue(p4_monitor_t* m, int i): Like condition variable notify- Based on architecture-specific lock implementations, which might include very slow implementations based on IPC
“The most useful monitor of all”
p4_askfor(p4_askfor_monitor_t* m, int nprocs, int (*getprob_fn)(), void* problem, int (*reset_fn)())
“requests a new ‘problem’ to work on from the problem pool. The arguments are
(1) a pointer to the askfor monitor that protects the problem pool, (2) the
number of processes that call this procedure (with af) looking for
work, (3) a pointer to the user-written procedure that obtains a problem from
the pool, (4) a pointer that is filled in with the address of a user-defined
representation of a problem to be solved, and (5) a pointer to a user-written
procedure to reset when all problems in the pool are solved, in case the same
monitor is re-used for another set of problems later. …
returns an integer indicating whether a problem was successfully obtained or
not”
- A work queue (or task queue)!
- One of the most fundamental data structures used in cluster computers too
- Scheduling, distribution, failure handling are key concerns
- We’ll see this again